Starting this week, we will do a series of four blogposts on the intersection of Spark with Kubernetes. The first blog post will delve into the reasons why both platforms should be integrated. The second will deep-dive into Spark/K8s integration. The third will discuss usecases for Serverless and Big Data Analytics. The last post will round off with insights on best practices.
Introduction
Most Cloud Native Architectures are designed in response to Digital Business initiatives – where it is important to personalize and to track minute customer interactions. The main components of a Cloud Native Platform inevitably leverage a microservices based design. At the same time, Big Data architectures based on Apache Spark have been implemented at 1000s of enterprises and support multiple data ingest capabilities whether real-time, streaming, interactive SQL platform while performing any kind of data processing (batch, analytical, in memory & graph, based) at the same time providing search, messaging & governance capabilities.
The RDBMS has been a fixture of the monolithic application architecture. Cloud Native applications, however, need to work with data formats of the loosely structured kind as well as the regularly structured data. This implies the need to support data streams that are not just high speed but also are better suited to NoSQL/Hadoop storage. These systems provide Schema on Read (SOR) which is an innovative data handling technique. In this model, a format or schema is applied to data as it is accessed from a storage location as opposed to doing the same while it is ingested.
Thus, Spark & Hadoop provides not just an ability to store large amounts of data but also provide multiple ways to process the data & support response times in milliseconds with the utmost reliability whatever be the data processing requirement – real-time data or historical processing of backend data.
On the other hand, enterprise applications are evolving into an infinite array of possible architecture flavors. At a minimum, any given enterprise has many kinds of application architecture and deployment flavors ranging from legacy mainframes to 3-tier applications to microservices. However, there is no argument that the march to containers as the foundation for applications has begun and will dominate the landscape for the years to come. Containers are rightly called out as the future of modern software delivery, and Kubernetes is the de facto standard for orchestrating them.
The story of 2019 is that these capabilities are increasingly being requested on the cloud as opposed to pure working on premises. And that is where Kubernetes comes in.
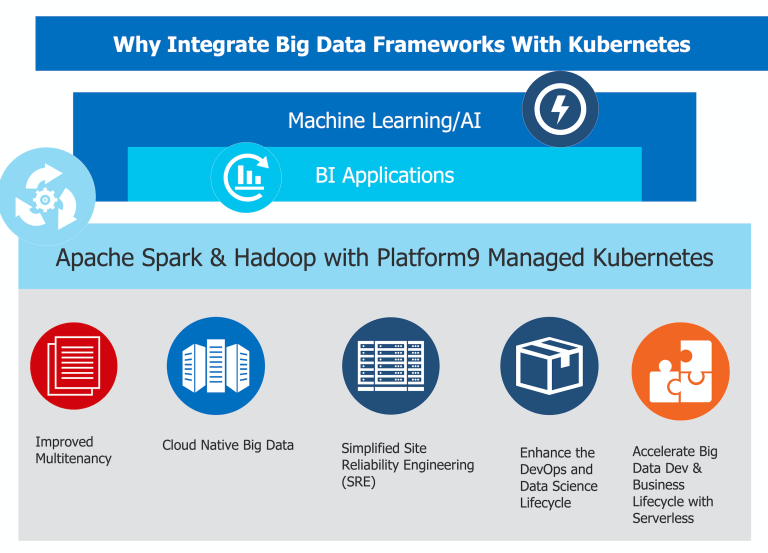
The benefits of combining Spark with Kubernetes.
#1 Get Rid of Big Data-IT silos and vastly improve Hardware usage & Multi-tenancy
Today, containers are used for the large-scale management of mainly web-related services and are slowly making their presence felt in data-enabled applications. Containers can be started up and shut down on demand much more readily than VMs, and popular cloud providers have added dedicated support for containers, making it easy to start up thousands of containers to service bursty workloads. Popular containers include Docker, CoreOS, and many others. Orchestration software such as Kubernetes provides enterprise-grade capabilities for managing containers. Furthermore, platforms, such as Kubernetes, not only provide support for managing containers but also add the capability of managing other legacy hardware for application-aware scheduling and other services. Running Spark based applications on containers and orchestrating them via k8s ensures that more IT silos & technical debt are not created. K8s standardizes how containers & pods that comprise any application are deployed, scaled and exposed to consumers via request routing. All of the semantics around HA, upgrades, monitoring, and troubleshooting are standardized via both API & an operational tooling standpoint. This eliminates a major pain point during the YARN years where Hadoop & Spark workloads were treated as a walled garden that required specialized skills.
#2 Enable Big Data with the k8s ecosystem
Big Data implementations in enterprise businesses enable the ability to drive continuous online interactions with global consumers/customers/clients. The goal is not just to provide engaging visualization but also to personalize services clients care about across multiple channels of interaction. Big Data has become the catalyst in this massive Digital movement as it can help business in any vertical solve their need to understand their customers better & perceive trends before the competition does. Big Data thus provides the foundational platform for successful business platforms. Cloud Computing services, on the other hand, can enable the easy delivery of Big Data platforms.
To support such architectures, popular open source projects such as NoSQL databases (MongoDB, Couchbase, Redis, etc), MySQL, Kafka, nginx, JupyterHub, TensorFlow, Keras, Flink, Zepplin, scikit-learn, Apache Tomcat/JBOSS, etc are all provided as containerized images. Leveraging an application catalog enables easy mix and match as well as deployment. Using Helm, such projects are packaged as Charts which can be stored, versioned and shared using a Chart repository. The repositories then constitute the application catalog which has certified, secure and stable open source projects for easy download and inclusion in a project.
According to the IDC, by 2020, Cloud-based Big Data Analytics is on track to outpace corresponding on-premise implementations by a factor of 4.5 from a spending standpoint. [1]
The key technology areas where Big Data & K8s intersect are –
- Data Science development and model deployment
- ETL and Data Preparation
- Streaming data analysis
- Analytics and Reporting
Expect to see more of these data ecosystem platforms moving to containers in the short term.
#3 Unified Site Reliability Engineering (SRE)
Site Reliability Engineering is a set of practices and culture tht is also a mindset and a set of engineering approaches to running better production systems—we build our own creative engineering solutions to operations problems. A key challenge operations teams in large enterprises have is to operate in a hybrid cloud manner where multiple clouds (on-premise VM, private cloud based on OpenStack, AWS, Azure, GCP, etc) run multiple types of applications. SRE become a must in terms of running large scale distributed systems – operational work such as provisioning, orchestrating and administering applications (across servers, VMs, Containers), proactive troubleshooting of issues across storage, and network & the tenants across these regions. Running data workloads on k8s helps with unified SRE for the entire cloud-native estate. This ensures that Big Data applications need to conform to non-functional requirements as well as account for strategies to prevent downtime resulting from hardware failures, network issues, and service unavailability.
#4 Enhanced Data Science DevOps Lifecycle
“Containers offer a logical packaging mechanism in which applications can be abstracted from the environment in which they actually run. This decoupling allows container-based applications to be deployed easily and consistently, regardless of whether the target environment is a private data center, the public cloud, or even a developer’s personal laptop. Containerization provides a clean separation of concerns, as developers focus on their application logic and dependencies, while IT operations teams can focus on deployment and management without bothering with application details such as specific software versions and configurations specific to the app” – Google Cloud on the benefits of containers
As can be seen from the above statement, containers can help accelerate the agile software development process. They do so by enabling the creation of application components using self-contained, efficient docker images. These images package their own dependencies and help increase the velocity of development through a full CI/CD process. Containers also provide a reduction in both size as well as processing overhead when compared with VM based monolithic applications. These images also support incremental development as well as “roll forward or rollback” based on versions. DevOps is a relatively new concept for most data scientists who always developed and deployed in the same monolithic environment as covered in the below blogposts.
#5 Accelerate Big Data with Serverless
We have written extensively about Serverless & FaaS in previous posts [2]. However, adding Serverless implementations on Big Data projects can enable a range of functionality from a faster DevOps cycle of testing models. For instance, there are a few key industry trends in evidence at the moment. The first is a move to enabling Data Scientists & Analytics Developers to be more productive by enabling Model development in a faster “prototype-dev-test-deploy” cycle. As seen above containers make this process more efficient by enabling a cleaner separation of concerns across both data scientists and operations. Serverless takes this a step further as any block of code can be converted into a function. This enables If analytic developer produced a piece of code, they want to quickly be able to test it without going through a whole new application dev-test lifecycle.
Digital projects ask for a lighter weight analytical lifecycle than typical software development projects. The other key industry trend driving this is the effort to make the Data Science to IT Ops interaction easier. In most enterprises, Data Science teams do not want to deal with IT Infrastructure and Ops Teams and vice-versa. Using complementary technologies such as FaaS (Functions as a Service)[2], model testing can be made easier instead of following a full dev/test lifecycle each time a test needs to happen. The ops team would build/test/publish/ deploy functions & push them to a Docker Repo which can invoke a FaaS framework, such as Fission, that then stands them up. The model then communicates with the apps using an API library and an API gateway as covered below.
When the ML/AI development process can adopt such a methodology, it would vastly simplify & accelerate model scoring, monitoring and retraining.
Business Capabilities
The combination of Big Data & Kubernetes can drive business usecases – key examples include –
- Obtaining a real-time Single View of an entity (typically a customer across multiple channels, product silos & geographies)
- Customer Segmentation by helping businesses understand their customers down to the individual micro level as well as at a segment level
- Customer sentiment analysis by combining internal organizational data, clickstream data, sentiment analysis with structured sales history to provide a clear view of consumer behavior.
- Product Recommendation engines which provide compelling personal product recommendations by mining real-time consumer sentiment, product affinity information with historical data.
- Market Basket Analysis, observing consumer purchase history and enriching this data with social media, web activity, and community sentiment regarding the past purchase and future buying trends.
The next blog in this series will deep-dive into a reference architecture for Spark and Kubernetes integration.
References
[1] IDC Worldwide Quarterly Cloud IT Infrastructure Tracker –
http://www.idc.com/getdoc.jsp?containerId=prUS43508918
[2] How Fission on Kubernetes Takes FaaS & Serverless From DevOps to NoOps
How Fission on Kubernetes Takes FaaS & Serverless From DevOps to NoOps
This article originated from http://www.vamsitalkstech.com/?p=7832
Vamsi Chemitiganti is a Tigera guest blogger. Vamsi Chemitiganti is Chief Strategist at Platform9 Systems. Vamsi works with Platform9’s Client CXOs and Architects to help them on key business transformation initiatives. He holds a BS in Computer Science and Engineering as well as an MBA from the University of Maryland, College Park.
————————————————-
Free Online Training
Access Live and On-Demand Kubernetes Training
Calico Enterprise – Free Trial
Network Security, Monitoring, and Troubleshooting
for Microservices Running on Kubernetes
Join our mailing list
Get updates on blog posts, workshops, certification programs, new releases, and more!


