Designing and maintaining networks is hard. When deploying Kubernetes in your on-prem data center, you will need to answer a basic question: Should it be an overlay network on top of an existing network, or should it be part of an existing network? The Networking options table provides guidelines to choose the right type of networking based on various factors. If you decide to use native peering (pre-dominant option for on-prem), you will have to configure the network to ensure availability in the event of network outage (ex. Cable disconnected, TOR switch failure etc.). We cover a typical L3 highly-available network design in this post.
A cluster spans multiple racks. In a L3 deployment, these racks have different CIDR ranges. So the nodes in different racks should be able to talk to each other. Referring to the diagram below, that traffic goes through the network fabric. If you want to build out such a lab for your own learning, here is the example.
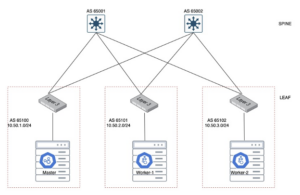
If you have a leaf-spine fabric with a single TOR (top-of-rack, or leaf switch), then that TOR becomes a point of failure for the entire rack. If all the master nodes are on the same rack, then the TOR failure effectively means cluster control plane outage.
This is a solved problem. Here are two popular options.
- MLAG (multi-chassis link aggregation) enables 2 links to different TORs acting as a single L2 link.
- Routing on the host with ECMP. Host becomes a L3 router as part of the network. So you have two L3 links from host to each TOR.
MLAG does not need special configuration. It is a bond interface on the node. We will focus on the 2nd topic in the context of Calico/Kubernetes. When considering Layer 3 connectivity from each node, note that there are 2 types of networks – one for the node, and one for the pods. From a node standpoint, every node in a rack connects to 2 TORs, each being part of a different CIDR. Both links are active-active. Even if a link/TOR goes down, the connectivity remains up.
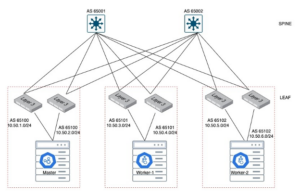
The other part is the pod network. Nodes are running individual pods and those pods talk to each other. The requirement for routing on the host can be summarized as: “to enable highly available networks for nodes and pods by integrating with network fabric”.
Calico Enterprise supports this as part of our configurable features. We often find this to be a difficult-to-configure feature because of the complexities involved. For the rest of this post, I am going to walk you through an end-to-end configuration for a dual TOR configuration in Calico Enterprise.
The Git repo for replicating the following is here. We will set this up using the following steps.
Required infrastructure
At least 4CPU and 12GB RAM. Good to run on your laptop. Tested with VirtualBox, Vagrant and Ansible, latest stable version. Clone the repo. Review the Vagrantfile for infrastructure details of leaf/spine switches and master/worker nodes.
Setting up the Cluster
Set up a cluster with racks to start: vagrant up leaf10 leaf11 leaf20 leaf21 spine1 spine2 k8s-master k8s-worker-1
b-3 git:(master) ✗ vagrant ssh k8s-master
...
vagrant@k8s-master:~$ kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-master Ready master 69m v1.18.1 192.168.200.1 <none> Ubuntu 18.04.4 LTS 4.15.0-76-generic docker://19.3.8
k8s-worker-1 Ready <none> 66m v1.18.1 192.168.201.1 <none> Ubuntu 18.04.4 LTS 4.15.0-76-generic docker://19.3.8
vagrant@k8s-master:~$
...
vagrant@k8s-master:~$ kubectl get po -A -owide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NO
DE READINESS GATES
calico-system calico-kube-controllers-7f95545d84-t68z6 1/1 Running 0 69m 10.10.235.194 k8s-master <none>
<none>
calico-system calico-node-599ds 1/1 Running 0 69m 192.168.200.1 k8s-master <none>
<none>
calico-system calico-node-dzfvc 1/1 Running 0 67m 192.168.201.1 k8s-worker-1 <none>
<none>
calico-system calico-typha-64ffdd88b5-7z9sc 1/1 Running 0 69m 192.168.200.1 k8s-master <none>
<none>
calico-system calico-typha-64ffdd88b5-fg9wd 1/1 Running 0 67m 192.168.201.1 k8s-worker-1 <none>
<none>
kube-system coredns-66bff467f8-578tg 1/1 Running 0 69m 10.10.235.195 k8s-master <none>
<none>
kube-system coredns-66bff467f8-647mw 1/1 Running 0 69m 10.10.235.193 k8s-master <none>
<none>
kube-system etcd-k8s-master 1/1 Running 0 69m 192.168.200.1 k8s-master <none>
<none>
kube-system kube-apiserver-k8s-master 1/1 Running 0 69m 192.168.200.1 k8s-master <none>
<none>
kube-system kube-controller-manager-k8s-master 1/1 Running 0 69m 192.168.200.1 k8s-master <none>
<none>
kube-system kube-proxy-klqx8 1/1 Running 0 67m 192.168.201.1 k8s-worker-1 <none>
<none>
kube-system kube-proxy-wg5wf 1/1 Running 0 69m 192.168.200.1 k8s-master <none>
<none>
kube-system kube-scheduler-k8s-master 1/1 Running 0 69m 192.168.200.1 k8s-master <none>
<none>
tigera-operator tigera-operator-84644cc5b8-5pw6g 1/1 Running 0 69m 192.168.200.1 k8s-master <none>
<none>
tigera-prometheus calico-prometheus-operator-588fdd8d9-wsj9z 1/1 Running 0 69m 10.10.235.192 k8s-master <none>
<none>
tigera-system tigera-apiserver-67b87557db-kd5gp 2/2 Running 0 67m 10.10.235.196 k8s-master <none>
<none>
vagrant@k8s-master:~$Note that we’re using the loopback/dummy interface of the nodes for Kubernetes control plane operation. This is critical. If the control plane is bound to an Ethernet interface, it will go down if the link goes down. Also, every Calico node peers with every other Calico node as shown below. This is called a full-mesh topology.
vagrant@k8s-master:~$ sudo calicoctl node status
Calico process is running.
IPv4 BGP status
+---------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+-------------------+-------+----------+-------------+
| 192.168.201.1 | node-to-node mesh | up | 16:14:50 | Established |
+---------------+-------------------+-------+----------+-------------+Our goal is to disable the peering between Calico nodes, and instead peer the Calico nodes to the TOR switches. Each Calico node runs a BGP daemon (BIRD) and does iBGP peering with the TORs.
Configure Dual TOR Peering
Apply appropriate AS numbers to Calico nodes.
vagrant@k8s-master:~$ calicoctl patch node k8s-master -p '{"spec":{"bgp": {"asNumber": "65101"}}}'
Successfully patched 1 'Node' resource
vagrant@k8s-master:~$ calicoctl patch node k8s-worker-1 -p '{"spec":{"bgp": {"asNumber": "65102"}}
Successfully patched 1 'Node' resource
vagrant@k8s-master:~$Label the nodes so that BGP peering can be applied based on the label.
vagrant@k8s-master:~$ kubectl label node k8s-master rack=rack1
node/k8s-master labeled
vagrant@k8s-master:~$ kubectl label node k8s-worker-1 rack=rack2
node/k8s-worker-1 labeled
vagrant@k8s-master:~$ kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-master Ready master 79m v1.18.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.
io/hostname=k8s-master,kubernetes.io/os=linux,node-role.kubernetes.io/master=,rack=rack1
k8s-worker-1 Ready <none> 77m v1.18.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.
io/hostname=k8s-worker-1,kubernetes.io/os=linux,rack=rack2
vagrant@k8s-master:~$ Create the BGP peering. You will find those commands here<.
vagrant@k8s-master:~$ kubectl apply -f - <<EOF
> ---
> # BGP peer configuration.
>
> apiVersion: projectcalico.org/v3
> kind: BGPPeer
> metadata:
> name: rack1-tor1
> spec:
> peerIP: 10.50.1.1
> asNumber: 65101
> nodeSelector: rack == 'rack1'
> sourceAddress: None
> failureDetectionMode: BFDIfDirectlyConnected
> restartMode: LongLivedGracefulRestart
> birdGatewayMode: DirectIfDirectlyConnected
> ---
> apiVersion: projectcalico.org/v3
> kind: BGPPeer
> metadata:
> name: rack1-tor2
> spec:
> peerIP: 10.50.2.1
> asNumber: 65101
> nodeSelector: rack == 'rack1'
> sourceAddress: None
> failureDetectionMode: BFDIfDirectlyConnected
> restartMode: LongLivedGracefulRestart
> birdGatewayMode: DirectIfDirectlyConnected
> ---
> EOF
bgppeer.projectcalico.org/rack1-tor1 created
bgppeer.projectcalico.org/rack1-tor2 created
vagrant@k8s-master:~$ Disable full-mesh and verify.
-master:~$ calicoctl apply -f - <<EOF
> apiVersion: projectcalico.org/v3
> kind: BGPConfiguration
> metadata:
> name: default
> spec:
> logSeverityScreen: Info
> nodeToNodeMeshEnabled: false
>
> ---
> EOF
Successfully applied 1 'BGPConfiguration' resource(s)
vagrant@k8s-master:~$ sudo calicoctl node status
Calico process is running.
IPv4 BGP status
+--------------+---------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+--------------+---------------+-------+----------+-------------+
| 10.50.1.1 | node specific | up | 17:34:33 | Established |
| 10.50.2.1 | node specific | up | 17:34:33 | Established |
+--------------+---------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
vagrant@k8s-master:~$We went from a node-to-node peering to node-to-fabric peering. Also note that the node is peered with 2 different TORs. At this point you can shut down an interface, or delete a TOR or Spine – and the Kubernetes nodes and pods should still be available. One thing you may have noticed is the static routes configuration on the TOR switches. It was necessary during bootstrapping of worker nodes. After bootstrapping, you can configure Calico Enterprise to advertise the loopback interface on the node and remove the static routes.
To summarize…
We reviewed native pod routing and dual TOR configuration for high availability. Native pod routing offers the following benefits.
- Performance and manageability. With growing services and ingresses, managing those and troubleshooting issues can be really difficult.
- Existing infrastructure integration, primarily with IT security and management processes. Existing products/systems/processes are long-lived and stable, and they mostly understand IP addresses (not pods).
A dual TOR configuration in Calico Enterprise enables you to build highly-available L3 networks on Kubernetes clusters.
————————————————-
Free Online Training
Access Live and On-Demand Kubernetes Tutorials
Calico Enterprise – Free Trial
Solve Common Kubernetes Roadblocks and Advance Your Enterprise Adoption
Join our mailing list
Get updates on blog posts, workshops, certification programs, new releases, and more!


