This blog post was written in collaboration with:
Aloys Augustin, Nathan Skrzypczak, Hedi Bouattour, Onong Tayeng, and Jerome Tollet at Cisco. Aloys and Nathan are part of a team of external Calico Open Source contributors that has been working on an integration between Calico Open Source and the FD.io VPP dataplane technology for the last couple of years.
Mrittika Ganguli, principal engineer and architect at Intel’s Network and Edge (NEX). Ganguli leads a team with Maria Butler, Qian Q Xu, Ping Yu, and Xiaobing Qian to enhance the performance of Calico and VPP through software and hardware acceleration.
This blog will cover what the Calico/VPP dataplane is and demonstrate the performance and flexibility advantages of using the VPP dataplane through a benchmarking setup. By the end of this blog post, you will have a clear understanding of how Calico/VPP dataplane, with the help of DPDK and accelerated memif interfaces, can provide high throughput and low-latency Kubernetes cluster networking for your environment. Additionally, you will learn how these technologies can be used to reduce CPU utilization by transferring packets directly in memory between different hosts, making it an efficient solution for building distributed network functions with lightning-fast speeds.
What’s the Calico/VPP dataplane?
Calico is the industry standard free and open-source networking and network security solution for containers, virtual machines, and native host-based workloads. The Calico Virtual Packet Processing (VPP) dataplane is the fourth addition to the pluggable dataplane arsenal, and it enables transparent userspace packet processing in areas such as service load balancing, encapsulation, policy enforcement, and encryption.
The Calico/VPP dataplane brings the performance, flexibility, and observability of VPP to Kubernetes networking. In addition to the standard Calico features, the Calico/VPP dataplane adds several features that enable new classes of workloads to run on Kubernetes. These features include new types of interfaces for different kinds of workloads, namely memif Cloud Native Network Functions (CNFs, these are typically packet processing workloads such as virtual routers or security appliances in a container form), which we’ll dig into below, and the VPP host stack interface for high-performance endpoint applications. The VPP dataplane is very focused on performance, but that’s not the only advantage it brings. Its flexibility also enables the easy development of novel features, such as MagLev load balancing, or the recent multi-network feature which brings several isolated, parallel networks to Kubernetes. These secondary networks also support all the standard Kubernetes network features, such as service load-balancing and policies.
Fast packet processing in Kubernetes with memif interfaces
Deploying high-performance packet processing applications or CNFs in Kubernetes is hard. By default, most CNIs provide the pods with a veth interface. While it’s possible to attach a CNF to that interface with an AF_PACKET socket, this will quickly be limited in performance, typically at around 1 Mpps. An alternative is the SR-IOV interface, typically added to a pod with Multus. This gives an optimal performance, but it also comes with some drawbacks: the applications that are deployed are dependent on specific hardware that must be present in the cluster, which is in limited supply on each node. In addition, the physical interfaces must be connected to some form of SDN that will take care of addressing, routing, and potentially firewalling. Finally, Kubernetes network features, such as policies, are not generally available on these interfaces. While it is possible to implement them outside of the cluster, the process is complicated.
Why use memif?
The memif feature in Calico/VPP, which provides pod connectivity through memif interfaces, is a new alternative to deploying high-performance packet processing applications or CNFs. Great performance aside, memif doesn’t have the drawbacks of SR-IOV interfaces: it doesn’t require special hardware and can be used on any cluster, and the Kubernetes network policies and service load balancing features are implemented on the traffic path.
Memif interfaces are straightforward packet interfaces that can be used to exchange packets between two processes and are based on a shared memory segment. A single thread can transmit or receive up to 15 Mpps on a memif interface! Memif interfaces support both L2 and L3 modes.
Memif in Calico/VPP
In Calico/VPP, memif interfaces can be requested for a pod simply by adding an annotation to the pod. The Calico/VPP CNI component will read this annotation when the pod is created. When the annotation is present, a memif interface will be created in the pod. The interface is exposed in the pod through an abstract unix socket associated with the pod namespace, making it easily available in all of the containers in the pod.
When a memif interface is present in a pod, a regular Linux network device is still created alongside it. This interface is used to carry the assigned IP address information, and can also be used by some processes running in the pod to send and receive traffic using the Linux kernel stack. Both the regular Linux netdev and the memif interfaces can be used interchangeably by the pod to send traffic. The traffic sent to the pod is directed to either the memif or the Linux interface, based on the destination port. The rules to configure this can be configured per pod using annotations. Here’s an example of a pod configuration that sends TCP traffic with destination port 9001 and UDP traffic with a destination port in the range 5000 to 5100 to the memif interface, with all the other traffic being sent to the Linux (tun/tap) interface:
Memif interfaces enable the running of packet processing applications, such as virtual routers, VPN, tunnel endpoints, or any other containerized network functions. Memif interfaces can be consumed by running VPP in the pod or by any Data Plane Development Kit (DPDK) application since DPDK supports memif. You can also consume them easily in your own applications written in C or Go using official memif libraries. As you’ll see below, memif provides much higher performance than the regular Linux datapath, with all the flexibility of a pure software implementation.
Calico/VPP performance benefits using DMA offloading
Using a simple setup with a forwarding application hosted in a pod over a Calico-VPP CNI, we can benchmark the performance of memif’s direct memory access (DMA) functionality.
Benchmark testing
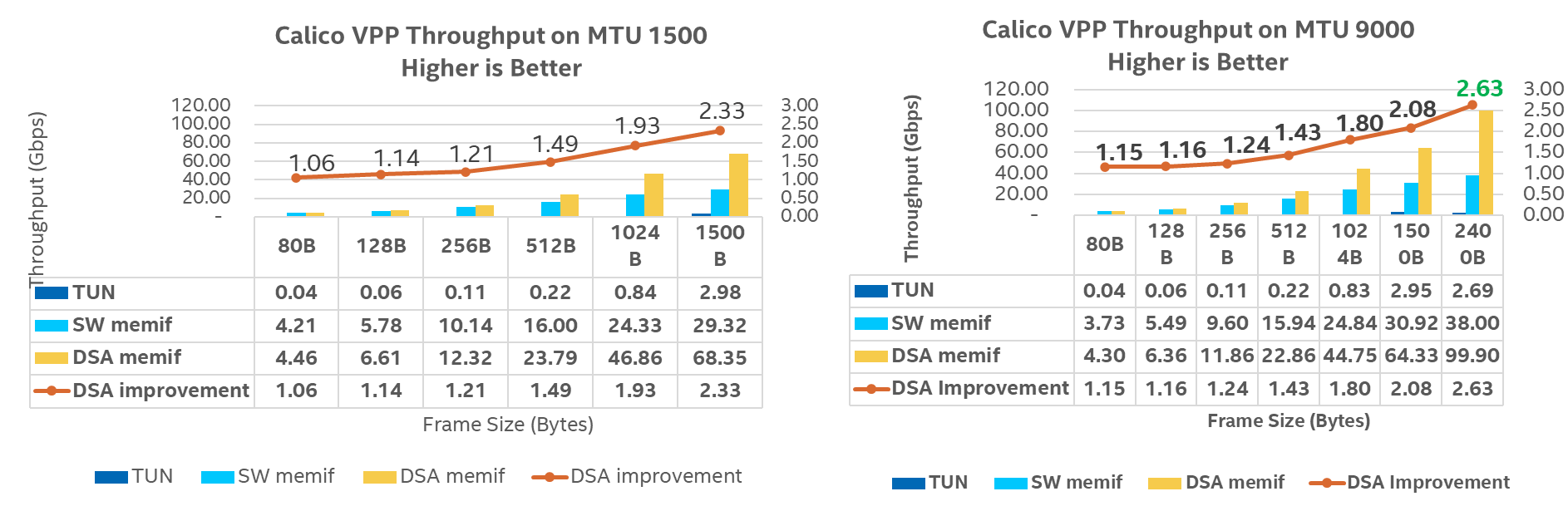
The benchmark demonstrates that the 4th Gen Intel® Xeon® Scalable processors with Intel® Data Streaming Accelerator (Intel® DSA) memory copy deliver up to 2.33x [MTU 1500, 1500B] and 2.63x [MTU 9000, 2400B] higher single-core throughput compared with a software memory copy. MTU 9000 has better performance for large packet sizes, while the tun interface has low throughput across all frame sizes (Figure 3). The results also indicate that Calico/VPP effectively utilized the full capacity of the CPU.
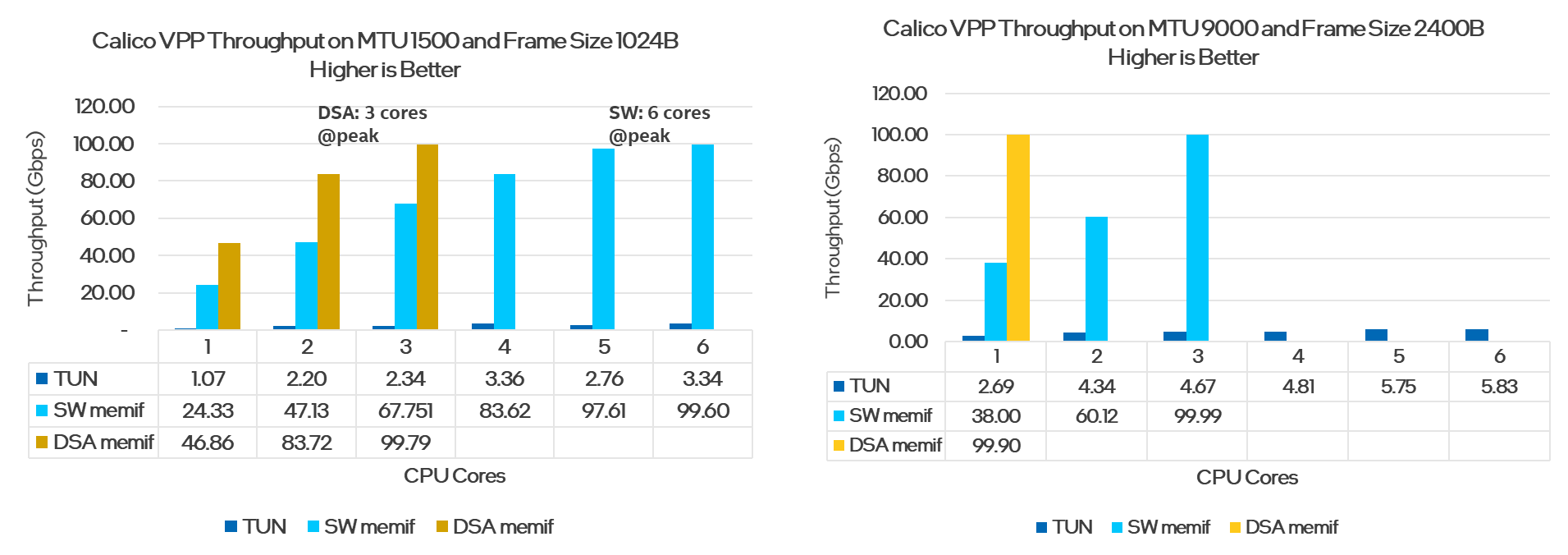
In summary, in the benchmark test with the 4th Generation Intel Xeon Scalable processor and the Intel DSA offload, we were able to achieve 100 Gbps throughput and save up to three cores, compared to just using the memif software with MTU 1500 and 1024B frame size. By using the 4th Gen Intel Xeon Scalable processor and Intel DSA with memif, we were able to save up to 2 cores and achieve 100 Gbps throughput compared to using the software memif with MTU 9000 and 2400B frame size (Figure 4).
Conclusion
In this article, we covered what Calico/VPP dataplane is, reasons to use memif, and demonstrated its performance capability through a benchmarking test. If you’d like to learn more about Calico and VPP, or share your ideas regarding VPP and Project Calico, please join our Slack channel, where you can connect with the developers behind the VPP project.
Ready to try Calico VPP and memif on your own cluster? Get started with VPP networking.
Configs:
Calico: 1-node, pre-production platform with 2x Intel® Xeon® Platinum 8480+ on Intel M50FCP2SBSTD with GB (16 slots/ 32GB/ DDR5 4800) total memory, ucode 0x9000051, HT on, Turbo on, Ubuntu 22.04 LTS, 5.15.0-48-generic, 1x 894.3G Micron_5300_MTFD, 3x Ethernet Controller E810-C for QSFP, 2x Ethernet interface, Calico VPP Version 3.23.0, VPP Version 22.02, gcc 8.5.0, DPDK Version 21.11.0, Docker Version 20.10.18, Kubernetes Version 1.23.12, ISIA Traffic Generator 9.20.2112.6, NIC firmware 3.20 0x8000d83e 1.3146.0, ice 5.18.19-051819-generic, Calico VPP Core Number: 1/2/3/4/5/6, VPP L3FWD Core Number: 1/2/3/4/5/6, Protocol: TCP, DSA: 1 instance, 4 engines, 4 work queues, test by Intel on 10/26/2022
Disclaimer:
- Performance varies by use, configuration, and other factors. Learn more at www.intel.com/PerformanceIndex
- Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
- Your costs and results may vary.
- Intel technologies may require enabled hardware, software, or service activation.
- Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
- The availability of accelerators varies depending on SKU. Visit the Intel Product Specifications page for additional product details.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Join our mailing list
Get updates on blog posts, workshops, certification programs, new releases, and more!


