
Does Tigera’s Calico Support BGP Unnumbered?
Lately, we’ve been talking quite a bit about network policy and security here in the Tigera blog. However, there is another aspect of Tigera’s solution, the underlying network platform that enables very scalable connectivity within the cluster itself, as well as to and from external resources. To reach cloud scale, we utilize a standard routing protocol (BGP) in private cloud deployments, as well as some public cloud environments as well.
A complete discussion of all of the network topologies that are possible with Tigera’s solutions is beyond the scope of this blog post, but a useful overview can be found in our documentation. For most folks, one of the models discussed there are quite sufficient, and we have large deployments using all of those models.
However, occasionally we get questions from folks who have some pre-existing BGP networking experience about alternative configurations. One that comes up is a two ToR model. I’ll cover that topic in a later post. Another one is “Do you support BGP unnumbered?” I’ll answer that question now, and explain a bit about what that is, and why people ask.
So what is BGP unnumbered anyway? (or, a tour through a chapter in BGP’s history
The original genesis of BGP came from the need to scalably pass large numbers of routes between Internet Service Providers. At the time BGP was developed, the existing routing protocols (e.g., OSPF and IS-IS) performed two functions, map an exact route to a given destination, and detect faults along the route. Combining these two functions meant that those protocols were (and still are) not scalable for large numbers of routes. The need for carrying large numbers of routes (all the ISP’s customer routes, and all of the routes of all the other Internet routes – currently the Internet routing table has more than 725K routes), led to the creation of BGP.
To reach the scale necessary, BGP behaves a bit differently than other routing protocols. To allow for scale, each network on the Internet is assigned a unique ID, called an Autonomous System Number (ASN). You can think of these as equivalent to country codes in the phone network, or zip/postal codes for postal mail. Two BGP routers that are communicating either are doing so within a given ASN (called iBGP) or between two ASNs (called eBGP). Each router also has one or more IP addresses that it uses as a next hop when it exchanges routes.
When a router learns about routes over an eBGP connection, it changes the next hop value of the route(s) to be one of its address(es). In effect, it is saying that it is the path to the given destination.
When that router then tells other routers in the AS (via iBGP sessions) those other routers do not change the next hop value, basically saying that the first router in the ASN that learned the route is the gateway for that route. A picture might make this easier to understand:
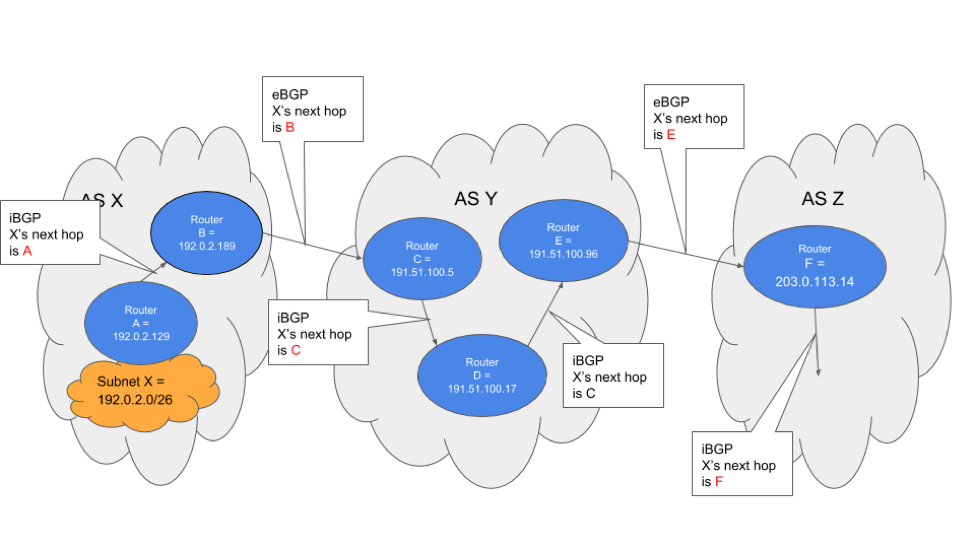
The diagram shows that next hop for the route to X changes when it crosses an AS boundary, but not when it is passed between routers in each AS. You can think of it that BGP tells you where you want to go, but not necessarily how to get there. In a large, diffuse network, that task is still carried out by an Interior Gateway Protocol (IGP) like OSPF or IS-IS. This can be seen in the following diagram (same network, but at the intra-AS routing layer).
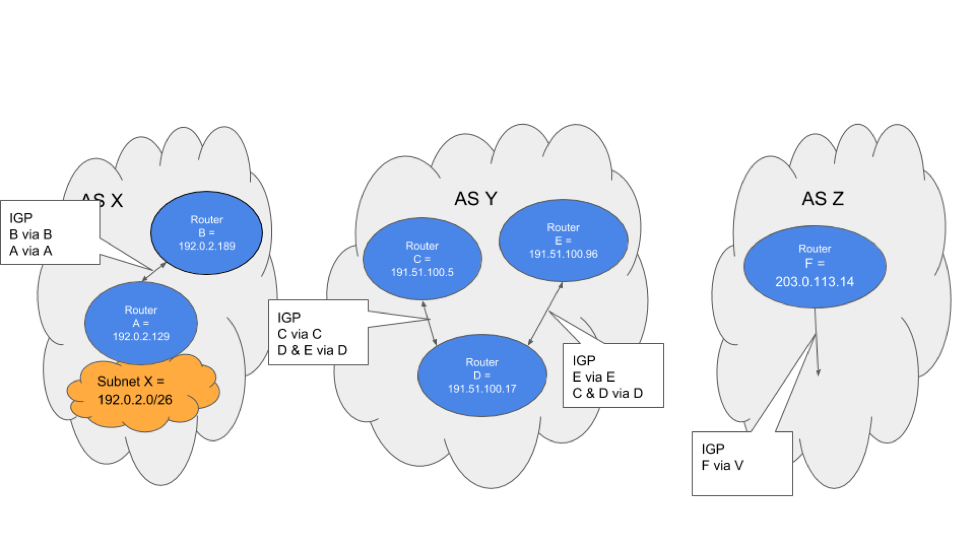 So, when a router wants to reach a specific destination, it uses BGP to find what router is the gateway to the desired destination itself, or at least the gateway to the next AS in the chain. It then (usually) uses an IGP to find how to get to that BGP routers next hop address.
So, when a router wants to reach a specific destination, it uses BGP to find what router is the gateway to the desired destination itself, or at least the gateway to the next AS in the chain. It then (usually) uses an IGP to find how to get to that BGP routers next hop address.
The examples in the diagram are simple, but in a service provider’s network BGP routers may have 10’s to 100’s of links. If you addressed each of them, it would have two effects:
- You would consume a lot of IP addresses just configuring each interface with an IP
- The next hop address would (potentially) be different depending on which link the route was being exchanged on. An example can be seen in the following diagram:
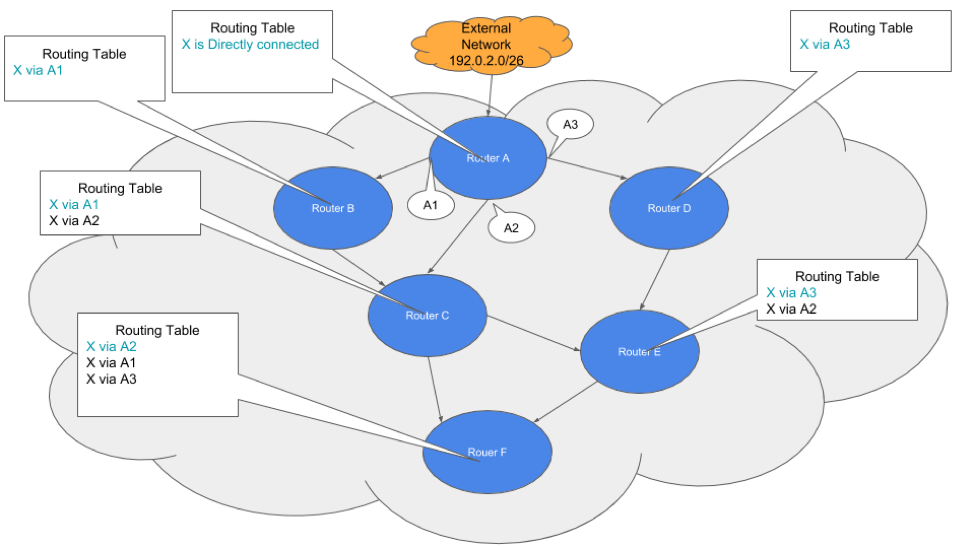
Point two also leads to a follow-on issue. Let’s say that router A2’s interface fails. That means that all of the routers that have A2 as the preferred route to X have to re-spin their routing tables to select the next best route. Even though the router A still exists. This is a little problem in this network, but in a network of 1000’s of routers with lots of links that routinely fail (I just described all service providers), this is not inconsequential.
To solve this, we moved the advertised next hop from the interface to the loopback of the router. This means that the routing tables for all of the routers (except A’s) would have a single entry for X with a next hop of A’s loopback. A smaller, and more stable, routing table. What’s not to like. This is called loopback peering.
To address point 1, once you have done loopback peering, you can, at least from BGP’s point of view, remove the IP addresses from the links. This is called unnumbered interfaces. This saves a lot of IP address space in a large service provider network, at the cost of some increase in complexity in troubleshooting. It will be quite confusing to someone who has not done it before, as many of the tools in use for troubleshooting will give non-standard answers, or won’t work at all.
Together, this is called unnumbered BGP. Not surprisingly, some of our customers and users who have network engineers and architects who used to work at service providers ask if this is something we can support. The answer, right now is, no, we do not support this model.
But it sounds cool, so why not?
The data center, even when it is full of Calico routers, does not approximate the complexity of a service provider network. The intra-data center links don’t run over rivers that flood, under streets that get dug up, or alongside where trains derail. They just don’t have the same per-capita failure rate of a service providers links. Also, there are much fewer links between any two routers. The most commonly deployed architecture is for a single ToR and its associated servers to be a single AS, with the connection between the ToR and the spine switch as an eBGP connection (in the diagram below, this would be the blue ToR only) This means that there is one interface between the servers (acting as routers In Tigera’s solution) and the ToR (acting as an eBGP router). Since there is only one interface, and each server needs an address, there is no benefit to the unnumbered model, and extra complexity (in troubleshooting) is introduced. Even in the cast of dual ToRs, which will be discussed in another blog post, there is limited benefit. In each case, the loss of a link between a server and ToR would cause the loss of the route to that server on that ToR, with the other ToR still able to reach the server via its connection. We do end up using 2 address per server, vs. one, but we retain ease of troubleshooting and maintenance. There is no real advantage to routing table size or stability to be gained by unnumbered in this case.
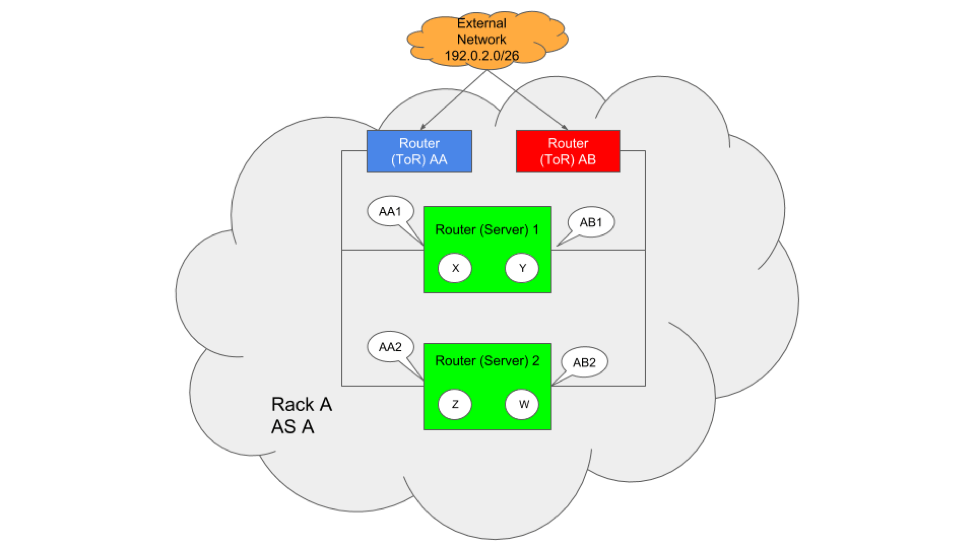 Furthermore, since most traffic will not be directed at the server, but at the workloads on the server (w, x, y, and z in the diagram), they will be announced over both links, much like a loopback, ensuring the same level of redundancy and reachability as would be achieved by using loopback peering (in fact, you can think of the workloads as individual loopback addresses).
Furthermore, since most traffic will not be directed at the server, but at the workloads on the server (w, x, y, and z in the diagram), they will be announced over both links, much like a loopback, ensuring the same level of redundancy and reachability as would be achieved by using loopback peering (in fact, you can think of the workloads as individual loopback addresses).
As we strongly believe that simplicity allows for scale, and maybe even more importantly, maintainability at scale, we have not implemented the features required to allow for BGP unnumbered.
But…
There is an interesting use case for unnumbered BGP loopback peering in an all IPv6 infrastructure, that would allow for true network auto-configuration. As the container community has not fully embraced IPv6 at this point, the discussion of this model is somewhat academic, but I may dive into it in another post if there is sufficient interest.
————————————————-
Free Online Training
Access Live and On-Demand Kubernetes Tutorials
Calico Enterprise – Free Trial
Solve Common Kubernetes Roadblocks and Advance Your Enterprise Adoption