What Is eBPF?
eBPF (Extended Berkeley Packet Filter) is a powerful Linux technology that allows developers to run sandboxed, custom programs directly inside the operating system kernel. It bypasses the need to modify kernel source code or load specialized modules, allowing for deep system observability, advanced networking, and real-time security without requiring system reboots.
eBPF is a kernel technology (fully available since Linux 4.4). You can conceive of it as a lightweight, sandboxed virtual machine (VM) within the Linux kernel. It allows programmers to run Berkeley Packet Filter (BPF) bytecode that makes use of certain kernel resources.
By building on existing kernel layers, this technology can fundamentally change how services such as observability, security, and networking are delivered.
How eBPF works:
- Hook points: eBPF programs attach to predefined hooks in the kernel, such as system calls, function entry and exit, network events, and tracepoints.
- Just-in-time (JIT) compilation: once an event triggers the program, its bytecode runs at near-native machine speed.
- The kernel verifier: an in-kernel verifier statically analyzes every program to confirm it terminates and cannot damage memory or crash the system.
Core use cases:
- Observability and tracing: hook into deep kernel and application functions to extract granular telemetry, track latency, and profile resource usage.
- Cloud-native networking: widely used in Kubernetes environments such as Cilium to build high-performance load balancers and route traffic with context awareness.
- Security and enforcement: monitor system and API calls, detect anomalous process behavior, and enforce firewall policies at the kernel level.
This is part of an extensive series of guides about observability.
In this article:
- eBPF Use Cases
- How eBPF Works
- How Are eBPF Programs Written?
- eBPF Basic Concepts and Architecture
- What is eBPF XDP?
- What is eBPF BCC?
- eBPF with Calico
eBPF Use Cases
Here are some of the important use cases for eBPF.
Security
Extending the basic capabilities of seeing and interpreting all system calls and providing packet and socket-level views of all networking operations enables the development of revolutionary approaches to system security.
Typically, entirely independent systems have handled different aspects of system call filtering, process context tracing, and network-level filtering. On the other hand, eBPF facilitates the combination of control and visibility over all aspects. This allows you to develop security systems that operate with more context and an improved level of control.
Learn more in our detailed guide to container security.
Networking
The combination of efficiency and programmability makes eBPF a good candidate for all networking solutions’ packet processing requirements. The programmability of eBPF provides a means of adding additional protocol parsers, and smoothly programs any forwarding logic to address changing requirements without ever exiting the Linux kernel’s packet processing context. The effectiveness offered by the JIT compiler offers execution performance near that of natively compiled in-kernel code. eBPF is also heavily used in cloud-native and Kubernetes environments, such as Cilium, to create high-performance load balancers and route traffic with context awareness.
Tracing and Profiling
The ability to attach eBPF programs to trace points in addition to kernel and user application probe points enables visibility into the runtime behavior of applications as well as the system.
By providing introspection capabilities to both the system and the application side, both views can be combined. This gives unique and powerful insights to troubleshoot system performance issues. Advanced statistical data structures let you extract useful visibility data in an effective way, without needing the export of huge amounts of sampling data that is typical for similar systems.
Observability and Monitoring
Rather than relying on gauges and static counters exposed by the operating system, eBPF allows for the generation of visibility events and the collection and in-kernel aggregation of custom metrics based on a broad range of potential sources.
This increases the depth of visibility that might be attained and decreases the overall system overhead dramatically. This is achieved by collecting only the required visibility data and by producing histograms and similar data structures at the source of the event, rather than depending on the export of samples.
How eBPF Works
eBPF programs are used to access hardware and services from the Linux kernel area. These programs are used for debugging, tracing, firewalls, networking, and more.
Developed out of a need for improved Linux tracing tools, eBPF was influenced by dtrace, a dynamic tracing tool available mainly for BSD and Solaris operating systems. Unlike dtrace, Linux was not able to achieve a global overview of running systems. Rather, it was restricted to specific frameworks for library calls, functions, and system calls.
eBPF is an extension of its precursor, BPF. BPF is a tool used for writing packer-filtering code via an in-kernel VM. A group of engineers started to build on the BPF backend to offer a similar series of features as dtrace, which eventually evolved into eBPF. Although initially released in limited capacity in 2014 with Linux 3.18, you need at least Linux 4.4 or above to make full use of eBPF.
The diagram below is a simplified illustration of eBPF architecture. Prior to being loaded into the kernel, the eBPF program needs to pass a particular series of requirements. Verification includes executing the eBPF program in the virtual machine.
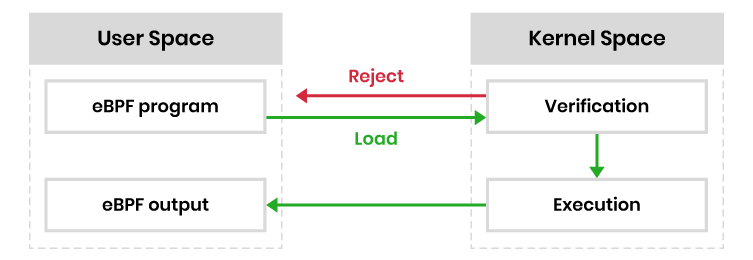
This permits the verifier, with 10,000+ lines of code, to carry out a set of checks. The verifier will go over the potential paths the eBPF program might take when executed in the kernel, to ensure the program runs to completion without any looping, which would result in a kernel lockup.
Additional checks—from program size, to valid register state, to out-of-bound jumps—should also be made. eBPF distinguishes itself from Linux Loadable Kernel Modules (LKM) by adding these additional safety controls.
If all checks are cleared, the eBPF program is loaded and compiled into the kernel at a location in a code path, and waits for the appropriate signal. When the signal is received in the form of an event, the eBPF program is loaded in the code path. Once initiated, the bytecode collects and executes information according to its instructions.
To summarize, the role of eBPF is to allow programmers to execute custom bytecode safely within the Linux kernel, without adding to or changing the kernel source code. Though it cannot replace LKMs altogether, eBPF programs introduce custom code that relates to protected hardware resources, with limited threat to the kernel.
How Are eBPF Programs Written?
In many cases, you might use eBPF indirectly through a project like bpftrace or Cilium. These projects offer abstractions on top of eBPF, so you don’t have to write the program directly. You can specify definitions based on intent, which eBPF then implements.
If there isn’t a higher level of abstraction that exists, you need to write the programs directly. The Linux kernel requires that you load eBPF programs in bytecode form. While it is technically possible to directly write in bytecode, this is not a popular option. Instead, developers usually prefer to compile pseudo-C code into eBPF bytecode using a compiler suite, such as LLVM.
Popular eBPF Tools
To get started writing or using eBPF, the open-source ecosystem offers several foundational projects:
- BCC (BPF Compiler Collection): a toolkit for writing eBPF programs, with front-ends in Python and Lua for tracing and manipulation (covered in more detail below).
- eBPF.io: the central community hub, with tutorials, reference documentation, and landscape maps of eBPF projects.
- eBPF for Windows: an open-source Microsoft project that brings eBPF capabilities to the Windows operating system.
eBPF Basic Concepts and Architecture
The architecture of an extended Berkeley Packet Filter includes the following elements.
Predefined Hooks
eBPF programs run according to events that trigger them. An application (or the kernel) passes a threshold known as a hook point. Hooks are predefined and can include events such as network events, system calls, function entry and exit, and kernel tracepoints. If there is no predefined hook for a certain requirement, you can create a user or kernel probe (uprobe or kprobe).
Program Verification
Once a hook is identified, the BPF system call can be used to load the corresponding eBPF program into the Linux kernel. This usually involves using an eBPF library. When a program is loaded into the kernel, it has to be verified to ensure it is safe to run.
Validation takes into account conditions such as:
- The program can only be loaded by a privileged eBPF process (unless otherwise specified).
- The program won’t damage or crash the system.
- The program will always run to completion (not sit in an endless loop).
eBPF Maps
An eBPF program must be able to store its state and share collected data. eBPF maps can help programs retrieve and store information according to a range of data structures. Users can access eBPF maps via system calls, from both eBPF programs and applications.
Map types include hash tables or arrays, ring buffer, stack trace, least-recently used, longest prefix match, and more.
Helper Calls
An eBPF program cannot arbitrarily call into a kernel function. This is because eBPF programs need to maintain compatibility and avoid being bound to specific versions of the kernel. Thus, eBPF programs use helper functions to make function calls. Helper functions are APIs provided by the kernel, and can be easily adjusted.
Helper calls allow programs to generate random numbers, receive current time and date, access eBPF maps, manipulate forwarding logic and network packets, and more.
Function and Tail Calls
These calls make eBPF programs composable. Function calls enable functions to be defined and called in a program. Tail calls enable the execution of other eBPF programs. They can also change the execution context.
What is eBPF XDP?
eBPF eXpress Data Path (XDP) allows for high-speed packet processing in the BPF application. To ensure a quicker response to network functions, XDP readily launches a BPF program, typically as soon as a packet is obtained from the network interface.
Learn more in our detailed guide to eBPF XDP
What is eBPF BCC?
BPF Compiler Collection (BCC) is a toolkit used to create effective manipulation and kernel tracing programs. It features various useful examples and tools. It requires Linux 4.1 or above.
eBPF BCC lets you attach eBPF programs to kprobes. This permits user-defined instrumentation on a functioning kernel image that can never hang or crash, and thus will not adversely affect the kernel.
BCC makes BPF programs simple to write with kernel instrumentation in C (and features a C wrapper around LLVM), including front-ends in Lua and Python. It can be used, for example, for network traffic and performance analysis.
eBPF with Calico
With its pluggable data plane architecture, Calico offers support for multiple data planes, including eBPF, standard Linux, nftables, and Windows HNS. This makes eBPF a powerful foundation for modern Kubernetes networking, service handling, and policy enforcement. Learn more in our detailed guide to eBPF for kubernetes.
Here are the key use cases for Calico eBPF:
- Improved Performance: The eBPF data plane scales to higher throughput and uses less CPU per GBit compared to standard networking Calico eBPF Installation.
- Enhanced Kubernetes Service Support: Calico eBPF provides native support for Kubernetes services without needing kube-proxy, which offers several benefits:
- Reduced first packet latency for service connections
- Preservation of external client source IP addresses all the way to the pod
- Support for DSR (Direct Server Return) for more efficient service routing
- Lower CPU usage for keeping the data plane in sync compared to kube-proxy Calico eBPF Installation
- Traffic Control Optimization: eBPF allows for optimizing the network path in the Linux kernel, bypassing complex routing, especially in Kubernetes container environments with multiple network stacks Calico eBPF Use Cases.
- Efficient Network Policy Implementation: eBPF enables efficient packet examination and application of network policies for both pods and hosts Calico eBPF Use Cases.
- Connect-time Load Balancing: eBPF allows for load balancing at the source of the connection, removing NAT overhead from service connections Calico eBPF Use Cases.
- Flexibility: Calico allows users to easily load and unload the eBPF data plane to suit their needs, providing the ability to leverage eBPF as an additional control for Kubernetes cluster security.
These capabilities also open the door to simplifying and accelerating service-to-service communication in environments that traditionally rely on sidecar proxies. Learn more in our detailed guide to eBPF service mesh.
Beyond the four data planes Calico currently supports, there are plans to add support for even more data planes in the near future, including Vector Packet Processing (VPP). Calico lets the user decide what works best for what they need to do.
Next steps:
- Get started with Calico’s eBPF data plane
- Documentation: Enable eBPF dataplane
- Read our blog eBPF: When (and when not) to use it
- Learn about kOps support for Calico eBPF data plan
- Learn how to resolve the Kubernetes container escape vulnerability using eBPF
See Additional Guides on Key Observability Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of observability.
Kubernetes Monitoring
Authored by Tigera
- [Guide] Kubernetes Monitoring: 6 Tools & 4 Best Practices You Must Know
- [Guide] 3 Pillars of Kubernetes Observability & 4 Things You Need to Get There
- [Blog] How Network Security Policies Can Protect Your Environment
- [Product] Calico Commercial Editions | Unified Network Security & Observability for Kubernetes
Cloud Security
Authored by Tigera
- [Guide] Cloud Security: Challenges and 5 Technologies That Can Help
- [Guide] Microsegmentation in the Cloud Native World
- [eBook] O’Reilly eBook: Kubernetes Security and Observability
- [Product] Calico | Unified Network Security & Observability for Kubernetes
Git Errors
Authored by Komodor