
We’ve been looking at our data plane performance lately, to confirm that Project Calico running on both VMs and containers really can achieve network throughput comparable to bare metal.
The results are much as we had expected; although there’s plenty more detail below, the key points are as follows.
- Calico can easily saturate a 10Gb/s link at an MTU of 1500 (which means not only an easier data centre configuration, but that traffic outside the data centre does not have to deal with the cost of fragmentation). That’s in marked contrast to Open vSwitch and VXLAN, for example, which to achieve similar bandwidth requires tuned TCP buffers and an MTU of 9000.
- There’s a CPU cost for any VM / container networking solution relative to bare metal networking; for VMs the traffic is being transmitted through an entire extra networking stack, while for containers there is an extra veth to traverse (unless the container shares the network namespace of the host). This CPU cost is shown clearly in our test results, and we have verified that Calico adds no significant overheads on top of it.
In other words, Calico is a very low overhead way of networking a container or VM deployment.
Testing methodology
In each case we used a combination of qperf and simple C programs to measure:
- CPU usage (both on the sending VM if applicable and on the host);
- raw throughput;
- packet latency.
For each configuration, we ran a number of times to rule out odd outlier results, and then took the mean results. To take out the external network as a factor, tests were run on two servers directly connected with 10Gb interfaces (using Intel X520-DA2 E10G42BTDA cards and SFP+ cables). We used TCP for our bandwidth measurements.
The two servers were both 8 core machines with 64GiB of RAM, running Ubuntu 14.04.2 with the 3.13 kernel (note the kernel version – there were some fixes in the 3.10 kernel for veth performance). We did no kernel tuning whatsoever, not even setting rmem or wmem, either on the hosts or the VM guests.
We ran in three different configurations.
- Bare metal – straight host to host, to provide a baseline.
- OpenStack VMs – all three options (VM to VM, VM to host, host to VM)
- Containers – again, all three options.
For each configuration we tried various message sizes. “Message size” here means the amount of data provided to each send call, and the size of the socket buffer – so a small message size implies a large number of writes to the kernel TCP buffer (even though in practice almost all TCP packets are close to the MTU size under this level of load, as the kernel has a continuous stream of data that it does an excellent job of combining into MTU sized packets). The results presented were all at an MTU of 1500.
Last but not least, as a sanity check we tried running a standard OpenStack deployment with Open vSwitch and VXLANs, on the same two physical servers but running CentOS (so that we could install with Packstack). Just as for Calico, we did no performance tuning of this deployment (and as will be seen below, this lack of tuning seemed to impact this topology far more than the Calico deployments).
Results – throughput and CPU
The key result can be seen in the following graph.
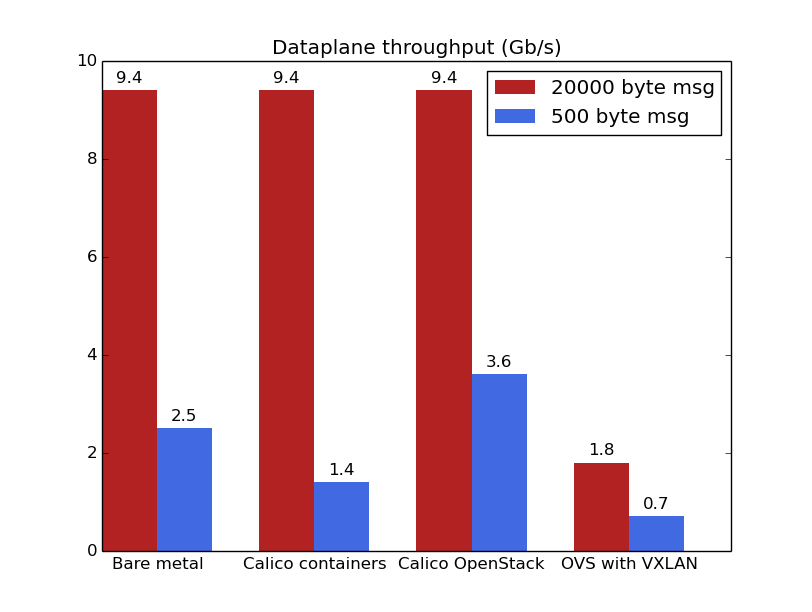
Concentrate on the red lines first – these show the throughput on the wire when the message size is 20,000 bytes (which in qperf terms means that the send buffer size is set to that length, and each send call tries to write an entire send buffer worth of data). Promisingly, bare metal, Calico containers and Calico OpenStack results are all the same. OpenStack using OVS with VXLAN is substantially lower (though with an increase of the MTU to 9000 the VXLAN throughput is pushed over 8Gb/s, getting into the same ballpark as Calico).
Looking at the blue lines though, something odd has happened. Why have the numbers dropped so much? And why does Calico on OpenStack have higher throughput than bare metal? The answer is visible from the next graph.
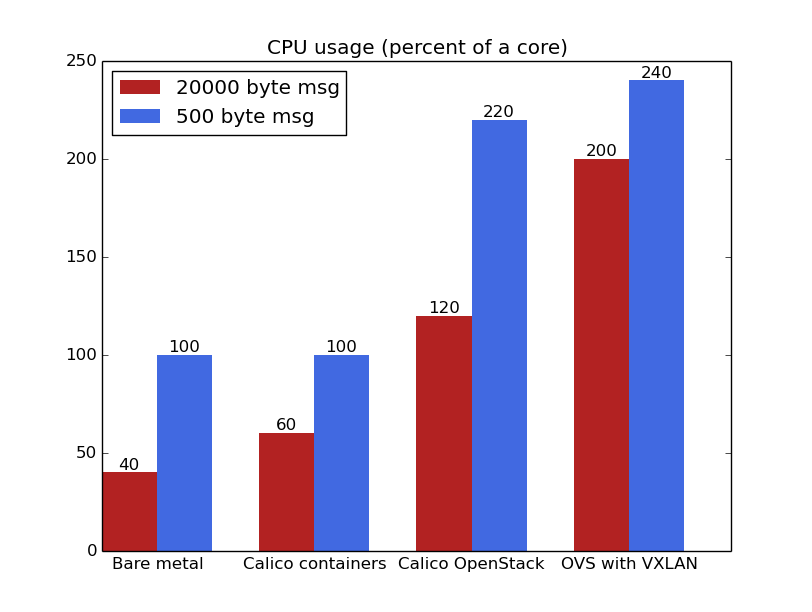
It’s clear that the limiting factor in throughput for lower message sizes is CPU, with both bare metal and container tests showing CPU pegged at 100% of a core. Every send call in the test tool requires a copy of the data into the kernel TCP buffer, and with 5 million send calls per second (against about a tenth as many with the larger message size), the CPU cost of that copy limits the throughput.
Calico with containers requires more CPU than bare metal to send the same amount of data because of the cost of the veth and the network namespace. Therefore when the CPU becomes the limiting factor in throughput, Calico containers are no longer able to keep up with bare metal.
By contrast, Calico with OpenStack actually achieves higher throughput – the send calls are combined into packets in the VM, while the network transmission is managed on the host, and so it manages to use more of the CPU (it can use one core on the host, and more than that on the VM itself).
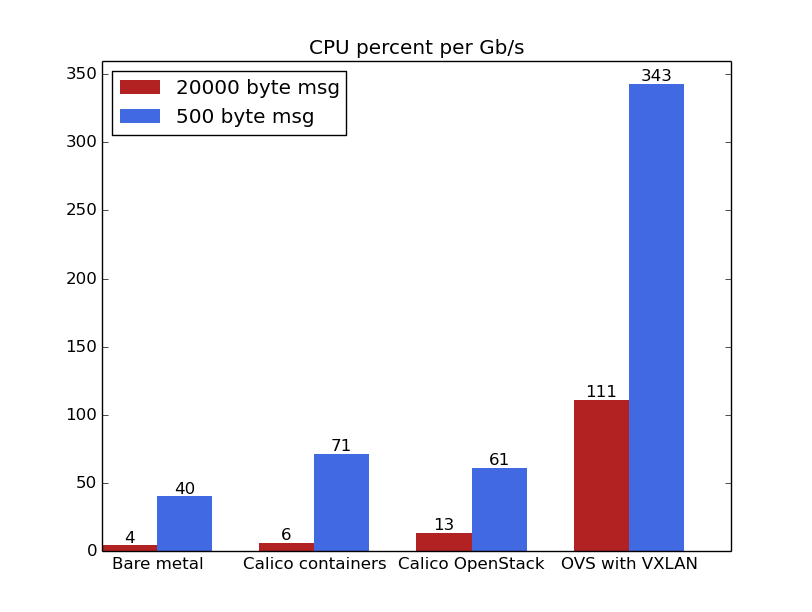
The above figure is simply the ratio of the data from the previous two, showing the CPU required to drive each Gb/s of throughput. The CPU shown is the higher of the sending and receiving side; in each case it was higher on the sending side, except for OVS plus VXLAN where the receiving side was higher.
The above discussion shows that there is a cost for virtualization or containerization compared to bare metal (the inevitable cost of traversing the virtual interface). To ensure that Calico itself wasn’t causing some of that extra cost, we compared performance of Calico containers with host traffic routed through an extra veth and network namespace, showing that the extra Calico cost is completely negligible.
Results – latency
Finally, some more numbers relating to latency. Here is the time taken for an exchange of a one byte payload TCP packet between the two endpoints.
- bare metal : 20 microseconds
- Calico containers : 25 microseconds
- Calico OpenStack VMs : 70 microseconds
- Open vSwitch plus VXLAN : 70 microseconds
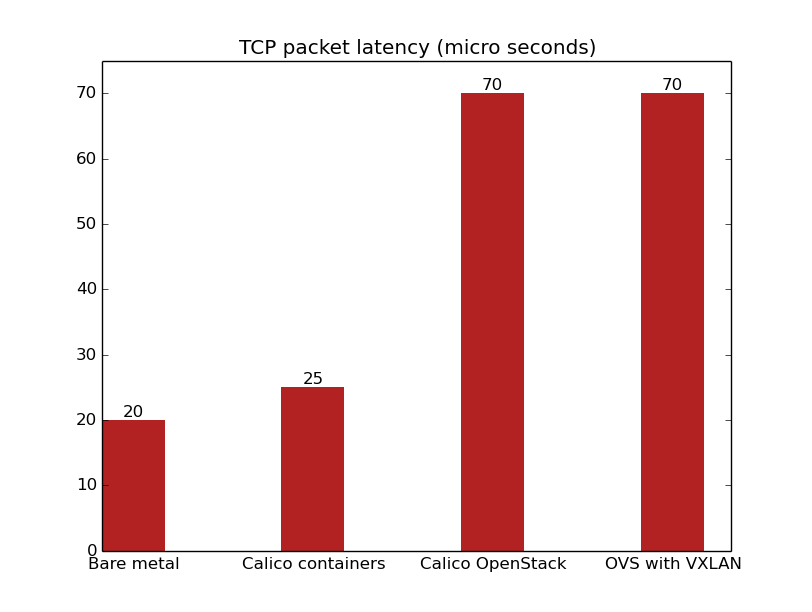
There’s clearly a greater latency cost in getting packets in and out of an endpoint through either a veth (which is barely measurable) or tap interface and through the extra network stack. However, the cost is small enough to be acceptable in most real world scenarios (and if you accept virtualization, it’s hard to do much better).
These are of course still relatively early results, and “your mileage will vary” depending on your precise deployment scenario, applications, etc. We welcome any comments on the methodology or other comparisons that people have done.