
Introduction
If you have workloads that are spread across multiple regions, zones, or racks, you may want to assign addresses from IP pools divided amongst the resource boundaries. Restricting IP addresses based on node topology can be useful if you want to reduce the number of routes required in a network or conform with enterprise network security policies.
One of the ways that you can express physical topology in Kubernetes is through labels. Labels are a fundamental mechanism for organizing resources inside of a Kubernetes cluster. By assigning a key-value pair to a resource, you can filter, select, modify, and constrain resources based on operational meaning. While labels are frequently associated with workloads and pods, they are also useful for describing the physical layout and configuration of nodes in a cluster.
Calico provides an IPPool resource that when used with topology described by node labels, lets you assign specific IP pools to nodes with specific labels. Although you can configure IP addresses for nodes in the CNI configuration file, it requires modifications to the host’s file system. Calico’s IPPool resource provides a more elegant and maintainable way to manage allocation of IP addresses.
IP Assignment Example
To illustrate how this works, consider an example where a cluster of four nodes is spread across two racks.
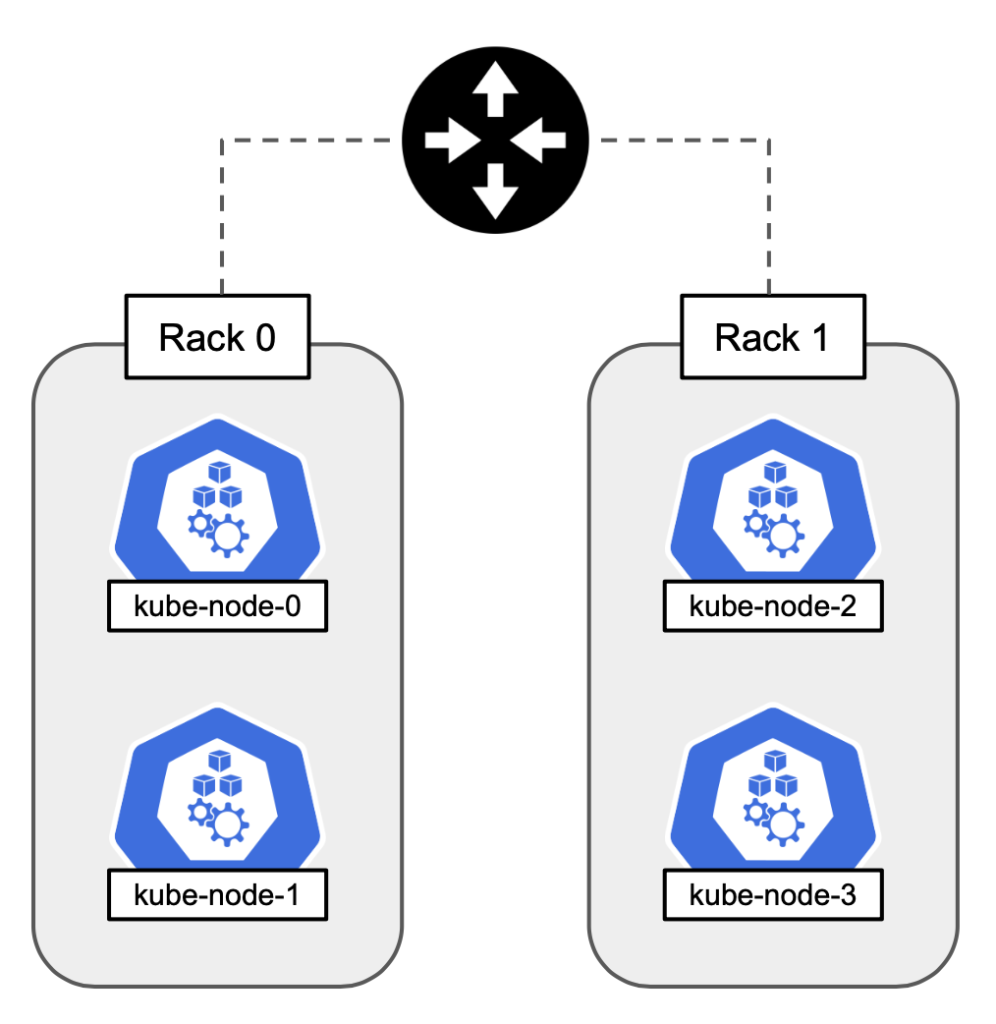
For the purposes of this example, assume that we’re working with the service IP range of 192.168.0.0/16. We will assign the subnets of 192.168.0.0/24 to rack 0, and 192.168.1.0/24 to rack 1.
By default a kubeadm or similar installation will assign a single IP Pool across the entire cluster. You can verify this with calicoctl:
$ calicoctl get ippool -o wide
NAME CIDR NAT IPIPMODE DISABLED SELECTOR
default-ipv4-ippool 192.168.0.0/16 true Always false all()We won’t be able to assign the subnets to the racks while the default-ipv4-ippool resource exists, since the /16 network completely contains the /24 networks. To correct this, start by deleting the default pool. Note that any workloads that already exist and have IP addresses assigned will not be changed. You will need to restart these workloads manually for changes to take effect.
$ calicoctl delete ippools default-ipv4-ippoolNext, label the nodes. To assign IP pools to specific nodes, these nodes must be labelled using kubectl label.
$ kubectl label nodes kube-node-0 rack=1
$ kubectl label nodes kube-node-1 rack=1
$ kubectl label nodes kube-node-2 rack=2
$ kubectl label nodes kube-node-3 rack=2Create an IP pool for each rack.
$ calicoctl create -f -<<EOF
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: rack-0-ippool
spec:
cidr: 192.168.0.0/24
ipipMode: Always
natOutgoing: true
nodeSelector: rack == "0"
EOF
$ calicoctl create -f -<<EOF
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: rack-1-ippool
spec:
cidr: 192.168.1.0/24
ipipMode: Always
natOutgoing: true
nodeSelector: rack == "1"
EOFWe should now have two enabled IP pools, which we can see when running:
$ calicoctl get ippool -o wide
NAME CIDR NAT IPIPMODE DISABLED SELECTOR
rack-1-ippool 192.168.0.0/24 true Always false rack == "0"
rack-2-ippool 192.168.1.0/24 true Always false rack == "1"To verify that the IP pool node selectors are being respected we will create an nginx deployment with five replicas to get a workload running on each node.
$ kubectl run nginx --image nginx --replicas 5Check that the new workloads now have an address in the proper IP pool allocated for the rack that the node is on with:
$ kubectl get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-5c7588df-prx4z 1/1 Running 0 6m3s 192.168.0.64 kube-node-0 <none> <none>
nginx-5c7588df-s7qw6 1/1 Running 0 6m7s 192.168.0.129 kube-node-1 <none> <none>
nginx-5c7588df-w7r7g 1/1 Running 0 6m3s 192.168.1.65 kube-node-2 <none> <none>
nginx-5c7588df-62lnf 1/1 Running 0 6m3s 192.168.1.1 kube-node-3 <none> <none>
nginx-5c7588df-pnsvv 1/1 Running 0 6m3s 192.168.1.64 kube-node-2 <none> <none>The grouping of IP addresses assigned to the workloads differ based on what node that they were scheduled to. Additionally, the assigned address for each workload falls within the respective IP pool that selects the rack that they run on.
Note that it’s important to assign at least one IP Pool to every node. Nodes will only assign workload addresses from IP pools which select them. If a node doesn’t have an IPPool assigned, a workload may not get an IP and fail to start. One mitigation for this potential problem is to create a default IP Pool with the default selector for all(). Then any node without a label that matches a location-specific pool will be captured by the default pool.
Summary
The pairing of Calico’s ability to manage IP Pools with Kubernetes node labeling gives you a means for allocating IP ranges based on physical infrastructure layout, whether that layout is as fine-grained as a rack or spread out across multiple regions. You can read more about this feature in the Project Calico How-To guide. You can catch up with the Calico team over on our Slack Channel, and get help over in the community Discourse. For up-to-date information on new blog posts and community meetings, head on over to @projectcalico on Twitter.
If you enjoyed this blog then you may also like:
- Calico IPAM: Explained and Enhanced
- Free online training workshops
- Learn about Calico Enterprise