A light in the mist
In my previous post on the topic of cloud microsegmentation, I pointed out that the existing models for network workload isolation or micro-segmentation were, at best, sub-optimal for the new cloud native world, and, most probably, just plain would not work at scale. In fact, I said:
“The historical model just isn’t tenable in a large scale micro-service environment where you want (or need) to implement zero-trust or least-privilege protections.”
Metadata is key to cloud native
What I also said was that networking is not the only area that has to change in a scale-out or cloud native world. One thing that needs to change is the concept of a single controller that is completely deterministic and the source of all truth in the infrastructure. What is needed, instead, is a system that enforces rules and policies based on the current state of the environment. Those rules and policies can be determined a priori and are independent of any specific state of the system. The number, location, and velocity of change of components in the system should be irrelevant to the operation of the system and the rendering of its policies.
The way that modern cloud native systems, such as Kubernetes, address this requirement is via zero-day configuration and metadata attached to workloads, services, hosts, etc. Depending on the state of the infrastructure and its applications, a given rule or policy may affect nothing in the infrastructure, everything in the infrastructure, or, more likely, some number in-between.
The other key component of this approach is that the rendering of those policies and rules needs to take place in as distributed and asynchronous manner as possible. The system can not assume convergence at any given point in time, but may assume eventual consistency. Any contrary assumption will lead to certain failure at scale.
“The system must respond to dynamic shifts in the environment based on pre-established rules and policies, enforced in as distributed a manner as possible.”
Networking as an Illustrative Example
I will be referring to my previous post here as an example case of how you might meet those requirements in a cloud-native, metadata driven environment. In fact, Tigera’s open source Project Calico implements the concepts I am going to discuss now.
One imperative of a cloud-native environment is to implement the concepts of ‘least privilege’ and ‘zero trust’ to improve the security of modern application infrastructures.
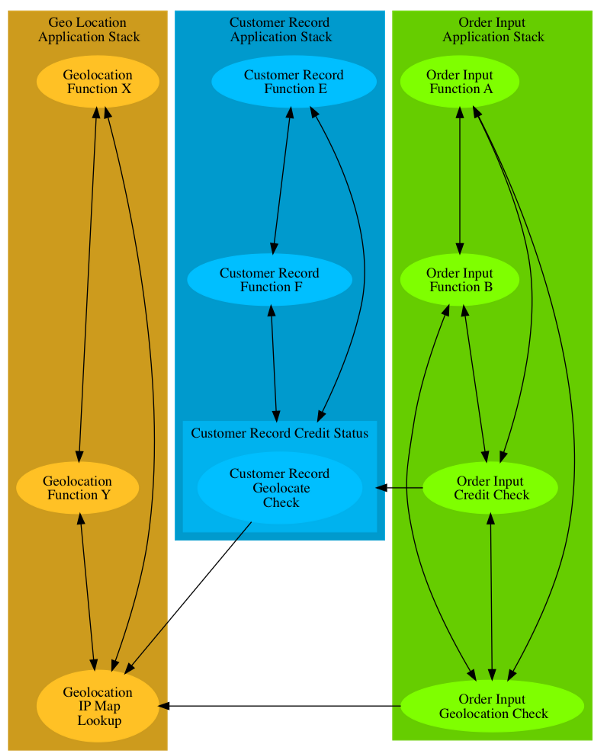
If you refer back to that post, you will see that we had three applications running in our infrastructure, Order Input, Customer Record, and Geo Location. Each of those applications were made up of multiple components, those included the Credit Check & Geolocation Check components of the Order Input application; the Credit Status component of the Customer Record application; and the IP Map component of the Geo Location application. I further postulated that a subset of the Credit Check component may need to talk to the IP Map component as well. The adjacent diagram represents the policy graph that needs to be enforced in the network. There are other components that are presented, beyond what was discussed in the original post, just as there would be in any realistic application stack.
Traditionally, least privilege has been hard
I have included some examples here, and applied a standard, if insecure, model where all components of a given application stack have connectivity to all other components in that stack. In the past that was done because it was quite difficult to provide fine-grained isolation between application stacks, let alone within them. What is shown in the diagram is a set of application stacks that are in transition. The concept of least privilege is being applied to inter-application traffic, but it has not yet been applied to intra-application traffic.
“The number, location, and velocity of change of components in the system should be irrelevant to the operation of the system and the rendering of its policies.”
Use the power of labels and metadata
To enable the desired state of least privilege in a very dynamic environment, we can use the labels and other metadata that the orchestration system attaches to the individual instances of each component. In the example above, every component might have two labels, one for the application stack it belongs to, and one for its function. For example, each instance of the Credit Check function of the Order Entry application might have the labels application=orderEntry and role=creditCheck applied to it and each instance of the Credit Status component of the Customer Record application might have the labels application=custRecord and role=creditStatus applied to it. All other instances of all components of the Customer Record application would also have the application=custRecord attached to them.
Let’s assume that there were two policies loaded in the system. One was a policy that only allowed traffic from things labeled role=creditCheck to connect to things labeled role=creditStatus. The other policy would allow any traffic as long as both ends of the connection were labeled application=custRecord.
“…rendering of those policies and rules needs to take place in as distributed and asynchronous manner as possible.”
An example of distributed enforcement
Let’s further assume that these application stacks are running in a Kubernetes environment that spans a large number of hosts and that there is an agent of some kind that resides on each of those hosts. Those agents would have the ability to interrogate the workload(s) (instance(s) of one or more components) present on the local host and also interrogate a list of policies and an inventory of all other workloads in the environment. When a workload is created or modified on that host, the local agent could see what labels are attached to that workload and compare that to a list of policies. If (and only if) a policy applied to a given workload, based on its labels, the agent would collect the necessary information from the inventory to render the policy(s) that applied to that workload.
In our example, if the new workload is an instance of the Credit Status component of the Customer Record application, then it would have the application=custRectord & role=creditStatus labels attached. That means that both of the policies I identified earlier would apply to this workload.
The agent would then interrogate the inventory of all workloads and find all of the workloads that asserted either the application=custRecord and/or role=creditCheck label(s). Using that list, the agent would then build a set of filters that would only allow the communications intended to be allowed by the policy. The key here is that each agent is doing this independently, and is only working when a change in the system affects a workload that it is managing. In a system of thousands of hosts, any given change may only trigger activity on one agent, all of them, or something in-between. The key thing is that the policy enforcement subsystem scales concurrently with the overall size of the system, and does so by leveraging policies and metadata.
This is the architectural model that underpins many of the cloud native platforms in use today — and is also the approach we take with Project Calico to provide dynamic micro-segmentation.
Join our mailing list
Get updates on blog posts, workshops, certification programs, new releases, and more!


