
I was discussing home security with a friend the other day as he was telling me about a fancy new Bluetooth lock he installed on his front door. He went on to explain how it provided status alerts and how he could remotely control it to let people in when if he wasn’t home. He was quite proud of the security he had implemented and asked what I thought about it.
I said, “That’s great. So, do you have a garage with an unlocked door to the main house? Ever leave your garage door opener in plain view in your car — possibly unlocked?” After a couple more questions about windows and basement exits, his illusion of security evaporated. He had failed to consider that the attack vector is just as important as the barrier. Hold that thought, we’ll get back to it in a bit.
This is the first of a 3-part blog series on Securing Host Endpoints With Project Calico.
- Part 1: What is a host endpoint and how is it different than a workload endpoint?
- Part 2: How do I write policies that match my intended traffic?
- Part 3: Securing endpoints in Kubernetes
This first part will focus on how we define an endpoint in Project Calico.
Microservices on the Network
Most organizations adopting cloud native principles are building and/or deploying applications composed of microservices. We won’t go into depth about microservices here but instead will assume that they are processes that interact with each other — most often via network calls. For an in-depth discussion on this approach, please see my colleague’s post on Micro-segmentation in the Cloud Native World.
To run microservices at scale, organizations typically leverage an orchestration platform and a form of workload virtualization — most likely virtual machines, containers, physical servers, or a hybrid mix of all three. The majority of these virtualization platforms rely on the isolation, routing, and filtering capabilities of the Linux kernel. Specifically, the Linux kernel connects each workload to the network as a first class citizen, that is, with a unique IP. Workloads can now interact in a consistent way with each other via the network without regard to how they are manifested or where they are located.
The network has become the common denominator for connecting workloads and has its own configuration and management burden. Things are further complicated when we add dynamic workload scheduling to the mix. Instead of manually keeping up with a constantly evolving network topology, Project Calico can make changes automatically since it is orchestrator-aware and can constantly monitor for changes and manage the network configuration for each workload.
We’ll assume you are familiar with networking in a container platform and focus our attention on how to filter the packets being sent between workloads.
Endpoint Types
When a process in a workload wishes to interact with processes in other workloads, such as sending or receiving data, it must bind to an IP address and port associated with an network interface within its own workload. The process isn’t concerned with how its workload is concretely connected to the network but only that it can communicate with other workloads. Since all traffic sent or received by a process in a workload must transit a network interface, this is an ideal location to intercept traffic and make policy decisions. In Project Calico, endpoints represent network interfaces.
Endpoints come in two flavors, host and workload.
Host endpoints represent network interfaces that are static from Project Calico’s perspective. Orchestrators do not manage the lifecycle of these endpoints — in some cases, the endpoint may even be unknown to the orchestrator. Project Calico must be made aware of host endpoints by manually adding them to its data model.
Workload endpoints on the other hand have lifecycles that are managed by an orchestrator and are typically created and destroyed in conjunction with scheduling and destroying workloads. Project Calico watches the orchestrator’s metadata for changes so that it can maintain a list of known workload endpoints.
In both cases, Calico must be able to identify the network interface of an endpoint and most importantly, to understand how traffic traverses these endpoints en route to its destination.
Let’s illustrate this with a couple of examples.
The following illustration depicts a Linux operating system (OS) installed on bare hardware. The hardware has a network interface card (NIC) directly connected to the network and Linux exposes it as eth0. There is no virtualization in this example. Each process running on the OS is bound to a unique IP address and port combination associated with the network interface eth0.
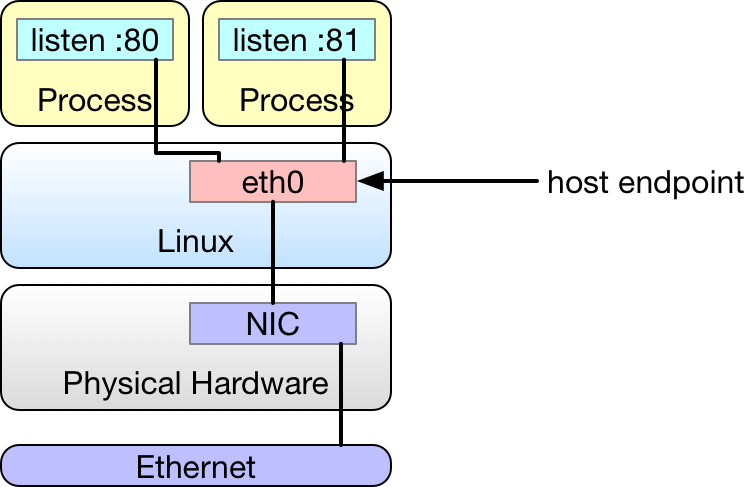
This could represent any number of legacy services, such as databases or web services not managed by a virtualization platform.
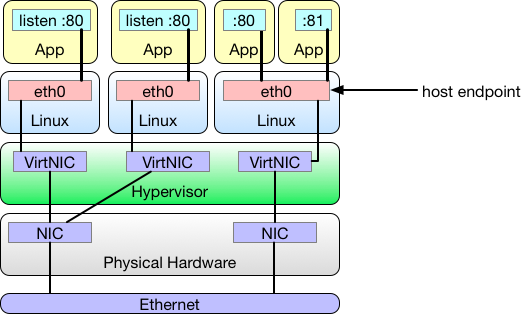
The only thing different in this next example is that the workloads are virtual machines. Project Calico sees each virtual machine as a workload and treats its network interfaces as host endpoints.
Things get more interesting when we start introducing containers. Each container has an eth0 network interface, which is in reality just one end of a virtual ethernet pair which carries packets from the container to the host for forwarding. Project Calico treats the host end of the pair as a workload endpoint.
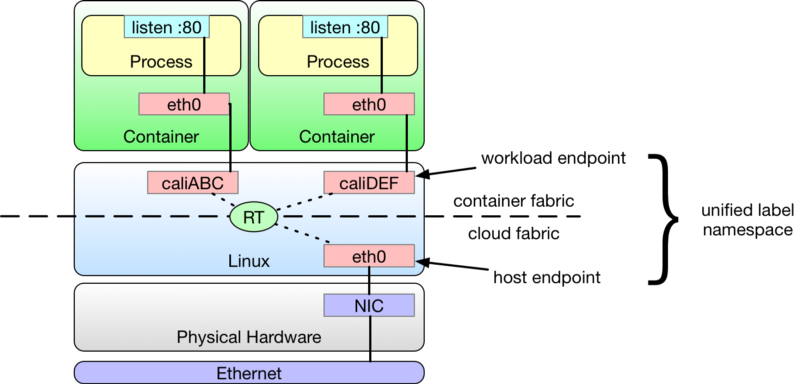
This configuration turns each node into a router. This is important because traffic bound for or originating from a container workload might transit both a workload endpoint and host endpoint.
Within the Calico policy data model, both types of endpoints can be associated with a set of labels. Where the orchestrator supports the concept of labels, such as Kubernetes, then these come from the orchestrator. Otherwise they can be applied to the endpoint via Calico’s APIs.
Now that we better understand the how a workload is connected to the network and the path data takes between two processes in separate workloads, we can revisit our opening discussion on attack vectors. Virtualized workloads are dependent on intermediate endpoints to forward traffic to and from the network. Therefore, we should not limit the scope of our security only to workload endpoints but rather to all endpoints in the in the data plane — controlling the traffic transiting each one with a unified policy framework.
We cannot adopt a zero-trust posture without this holistic approach. The first step towards this goal is ensuring our policies are targeting the right traffic at the right transit point. In Part 2, we will discuss how to write policies that match this traffic and learn which endpoints to associate these policies with.