Connection tracking (“conntrack”) is a core feature of the Linux kernel’s networking stack. It allows the kernel to keep track of all logical network connections or flows, and thereby identify all of the packets which make up each flow so they can be handled consistently together.
Conntrack is an important kernel feature that underpins some key mainline use cases:
- NAT relies on the connection tracking information so it can translate all of the packets in a flow in the same way. For example, when a pod accesses a Kubernetes service, kube-proxy’s load balancing uses NAT to redirect the connection to a particular backend pod. It is conntrack that records that for a particular connection, packets to the service IP should all be sent to the same backend pod, and that packets returning from backend pod should be un-NATed back to the source pod.
- Stateful firewalls, such as Calico, rely on the connection tracking information to precisely whitelist “response” traffic. This allows you to write a network policy that says “allow my pod to connect to any remote IP” without needing to write policy to explicitly allow the response traffic. (Without this you would have to add the much less secure rule “allow packets to my pod from any IP”.)
In addition, conntrack normally improves performance (reduced CPU and reduced packet latencies) since only the first packet in a flow needs to go through the full network stack processing to work out what to do with it. See the “Comparing kube-proxy modes” blog for one example of this in action.
However, conntrack has its limits…
So, where does it break down?
The conntrack table has a configurable maximum size and, if it fills up, connections will typically start getting rejected or dropped. For most workloads, there’s plenty of headroom in the table and this will never be an issue. However, there are a few scenarios where the conntrack table needs a bit more thought:
- The most obvious case is if your server handles an extremely high number of simultaneously active connections. For example, if your conntrack table is configured to be 128k entries but you have >128k simultaneous connections, you’ll definitely hit issues!
- The slightly less obvious case is if your server handles an extremely high number of connections per second. Even if the connections are short-lived, connections continue to be tracked by Linux for a short timeout period (120s by default). For example, if your conntrack table is configured to be 128k entries, and you are trying to handle 1,100 connections per second, that’s going to exceed the conntrack table size even if the connections are very short-lived (128k / 120s = 1092 connections/s).
There are some niche workload types fall into these categories. In addition, if you’re in a hostile environment then flooding your server with lots of half-open connections can be used as a denial-of-service attack. In both cases, conntrack can become the limiting bottleneck in your system. For some scenarios tuning conntrack may be sufficient to meet your needs by increasing the conntrack table size or reducing conntrack timeouts (but if you get this tuning wrong it can lead to a lot of pain). For other scenarios, you need to bypass conntrack for the offending traffic.
A real-world example
To give a concrete example, one large SaaS provider we worked with had a set of memcached servers running on bare metal servers (not virtualized or containerized) each handling 50k+ short-lived connections per second. This is way more than a standard Linux config can cope with.
They had experimented with tuning conntrack configuration to increase table sizes and reduce timeouts, but the tuning was fragile, the increased RAM use was a significant penalty (think GBytes!), and the connections were so short-lived that conntrack was not giving its usual performance benefits (reduced CPU or packet latencies).
Instead, they turned to Calico. Calico’s network policies allow you to bypass conntrack for specific traffic (using the doNotTrack flag). This gave them the performance they needed, plus the additional security benefits that Calico brings.
What are the trade-offs of bypassing conntrack?
- Do-not-track network policy typically has to be symmetric. In the SaaS-provider’s case their workload was internal so using network policy they could very narrowly whitelist traffic to and from all workloads that were allowed to access the memcached service.
- Do-not-track policy is oblivious to the direction of the connection. So in the event that a memcached server was compromised, it could in theory attempt to connect out to any of the memcached clients so long as it used the right source port. However, assuming you correctly defined network policy for your memcached clients then these connection attempts will still be rejected at the client end.
- Do-not-track network policy is applied to every packet, whereas normal network policy is only applied to the first packet in a flow. This can increase the CPU cost per packet since every packet needs to be processed by network policy. But with short-lived connections this extra processing is outweighed by the reduction in conntrack processing. For example, in the SaaS provider’s case, the number of packets in each connection was very small so the additional overhead of applying policy to every packet was a reasonable trade-off.
Putting it to the test
We tested a single memcached server pod and a multitude of client pods running on remote nodes so we could drive very high connections per second. The memcached server pod host had 8 cores and a 512k entry conntrack table (standard setting for the size of the host). We measured performance differences between: no network policy; Calico normal network policy; and Calico do-not-track network policy.
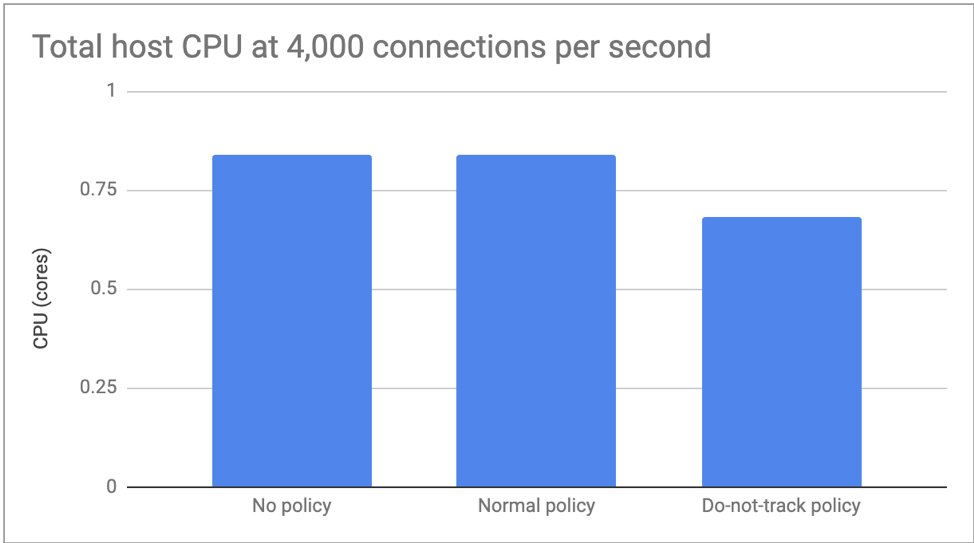
In the first test we limited the connections to 4,000 per second so we could focus on CPU differences. There was no measurable difference in performance no policy and normal policy, but do-not-track policy reduced CPU usage by around 20%.
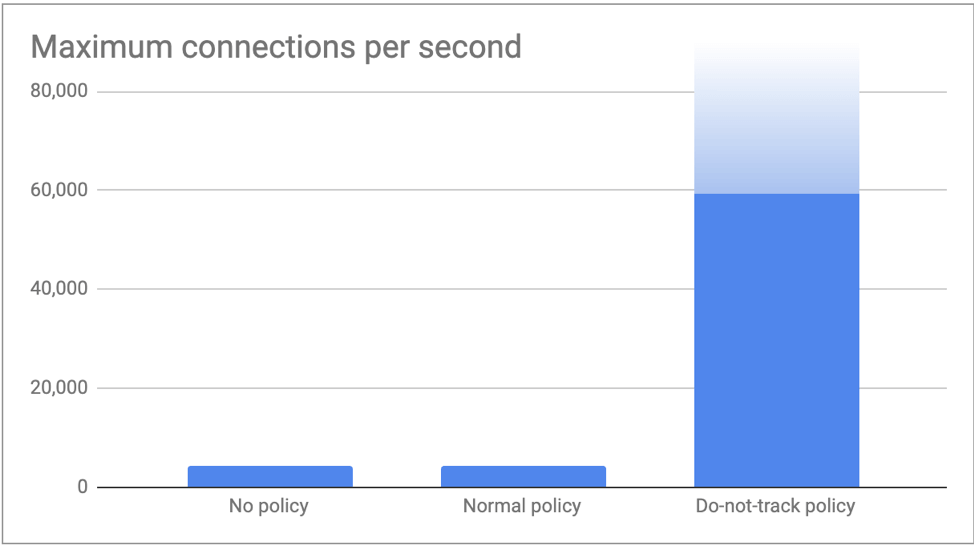
In the second test, we pushed as many connections as our clients could muster and measured the maximum number of connections per second the memcached server was able to process. As expected, no policy and normal policy both hit the conntrack table limit at just over 4,000 connections per second (512k / 120s = 4,369 connections/s). With do-not-track policy in place our clients pushed 60,000 connections per second without hitting any issues. We are confident we could have pushed beyond this by spinning up even more clients, but felt the numbers were already enough to illustrate the point of this blog!
Conclusion
Conntrack is an important kernel feature. It’s good at what it does. Many mainline use cases depend on it. However, for some niche scenarios, the overhead of conntrack outweighs the normal benefits it brings. In these scenarios, Calico network policy can be used to selectively bypass conntrack while still enforcing network security. For all other traffic, conntrack continues to be your friend!
If you enjoyed this blog then you may also like:
- Introducing the Calico eBPF dataplane including performance benchmarking and new service routing options with source IP preservation and DSR (Direct Server Return)
- Free online training at projectcalico.org/events or subscribe to Calico Essentials for personalized training & workshops
- Learn about Calico Enterprise
Join our mailing list
Get updates on blog posts, workshops, certification programs, new releases, and more!