There has been a huge uptick in microservices adoption in the data analytics domain, primarily aided by machine learning (ML) and artificial intelligence (AI) projects. Some of the reasons why containers are popular among ML developers is the ease of portability, scalability, and quick access to data using services—specifically network services. The rise of cloud-native applications, especially for big data in the analytics sector, makes these applications a prime target for cyber crime.
This article talks about what organizations need to know about zero trust for cloud-native workloads, and how zero trust for the cloud is different from a traditional zero trust network.
Challenges
Preventing threat actors from breaching the network and accessing critical data or applications is a daunting task for one team or individual to take on alone. DevOps and security engineers, SREs, and platform architects all need to work together to facilitate the process. These teams are usually presented with two challenges:
- Since the fundamental architecture model of microservices is distributed, it is imperative that east-west traffic is present. With most common deployments using a multi-cloud or hybrid model, there is no real network perimeter.
- One or more microservices will access external services such as 3rd-party cloud services, APIs, and applications, resulting in multiple ingress/egress points for north-south traffic.
What is zero trust?
Various approaches have been used to secure traditional workloads, including the use of security zones with different firewall rules for each zone, filtering traffic through access-lists, and using Virtual Private Networks (VPNs) for remote access. All of these approaches operate under a common assumption: the inside network is trusted; the outside network is not. This is a problematic way of thinking about security, and has led to many external and insider threats such as data exfiltration, and lateral threats such as malware and ransomware.
Eventually, organizations understood that a different approach was needed, which led to the concept of the zero trust network—where nothing is trusted and everything must be verified. About a decade ago, industry analysts and security companies jointly agreed that zero trust was the best defense against bad actors. The endorsement came in the form of the United States Federal Government filing an executive order for agencies to meet certain cyber security standards that align with the zero trust maturity model by the end of FY 2024.
Zero trust is a security model that enforces strict verification for any user, service or device attempting to access a network and its assets
The core pillars of zero trust based on CISA’s (Cybersecurity and Infrastructure Security Agency) maturity model are:
- Identity – Continuous verification (passwords, multi-factor authentication)
- Device – Compliance enforcement
- Network/Environment – Macro or microsegmentation
- Application workload – Access-based control
- Data – Least privilege, encrypted
Zero trust for cloud-native workloads
In a cloud-native environment, securing and monitoring individual pods or nodes is a challenge. When virtual machines (VMs) replaced legacy servers, it was still fairly easy to configure firewalls because these VMs were mostly static in nature. But the granular components of microservices (e.g. pods) are dynamic and short-lived—sometimes having a lifespan of only a few minutes—and have a bigger footprint (increased attack surface) for the same type of work a monolithic application had. Assume that you have solved the problem of securing these small workloads by putting a firewall around each node or pod. The threat might still be lurking in your network, originating from the inside.
Zero trust for cloud workloads enforces strict verification for any access to and from workloads
When you think about how difficult it is to design a security strategy for cloud-native workloads, the only logical solution is to follow how cloud-native applications are built. Building a zero-trust network with perimeter firewalls using IP addresses to create zones and policies will never work, because the addresses keep changing when pods restart. Kubernetes and other container based solutions are declarative in nature (i.e. any configuration change is handled by code) and policies are based on labels or DNS, rather than IP addresses. Using the same principles, security professionals can implement policies using cloud-native procedures for their security use cases.
Where should I start?
To understand where to start and how to build a zero-trust model for your Kubernetes or container based design, you need to identify your network’s protect surface (what’s most valuable to your organization) and understand its attack surface. The idea behind zero trust is to protect critical business assets, including customer data.
In order to understand your attack surface, you need to look at your applications and related communication and access. For cloud-native applications, each microservice will need to communicate not only with other microservices within a cluster, but in certain cases with external services (e.g. a SaaS service, APIs, or applications residing in a private data center), while you are running your clusters on a public cloud.
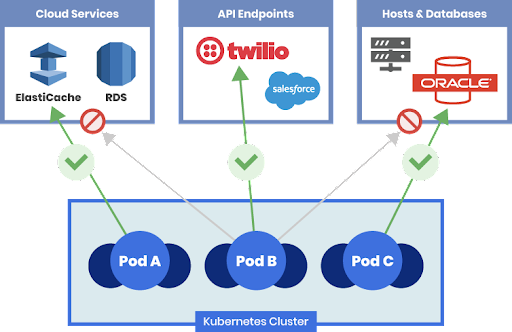
When it comes to network connectivity within a Kubernetes cluster, all pods can communicate with each other by default. A good security principle is to identify the function of each workload, and this is where DevOps best practices come in handy. Now that we have identified which component to provide authorization and access to based on its identity (function of a microservice, such as storefront-compliance), the next step is to create policies for least privilege access. This will ensure that only certain workloads can communicate with certain other workloads with a set of associated conditions validated, based on ports, service accounts, etc. (Never trust, always verify.)
What we have achieved through this process is effectively reducing the attack surface when a security breach happens. The more control we have over traffic sent from workload to workload, the more control we have over lateral movement of malware when there is a need to isolate infected workloads.
In the next post in this series, I will introduce Calico Cloud and show how it can help you identify and isolate workloads that are running Log4j. Stay tuned…
To learn more about how to adopt a holistic approach to container and cloud-native application security and observability, read our free O’Reilly ebook.