Yes, you read that right—in the comfort of your own laptop, as in, the entire environment running inside your laptop! Why? Well, read on. It’s a bit of a long one, but there is a lot of my learning that I would like to share.
I often find that Calico Open Source users ask me about BGP, and whether they need to use it, with a little trepidation. BGP carries an air of mystique for many IT engineers, for two reasons. Firstly, before its renaissance as a data center protocol, BGP was seen to be the domain of ISPs and service provider networks. Secondly, many high-profile and high-impact Internet outages have been due to BGP misuse or misconfiguration.
The short answer to the question is that in public cloud Kubernetes deployments, it is almost never necessary to configure or use BGP to make best use of Calico Open Source. Even in on-premise Kubernetes deployments, it is only needed in certain scenarios; you shouldn’t configure BGP unless you know why you need it. It is even less common to require complex BGP setups involving route reflectors and the like.
However, in certain on-premise scenarios, such as when direct (un-NATed) pod and service reachability from outside the cluster is desired, BGP can be a powerful tool. As luck would have it, I think it’s also extremely interesting to learn about!
The reality is that BGP is fundamentally not complex, but as with many routing protocols, its successful deployment involves an understanding of some subtle cause-and-effect.
With all that said, wouldn’t it be great to be able to dabble with Calico and BGP in a totally safe, zero-cost, and easily (!!) reproducible local laptop or workstation environment?
If you agree, I’m here for you. In this post, I’ll show you how I built two four-node Kubernetes clusters, peering with BGP, all inside my laptop, and how you can do the same.
As well as sharing what I learned while I built this environment, the steps I describe in this post will set us up well with an environment that we can use for later blog posts. For example, to investigate the cool new CalicoNodeStatus API that lets you view the status of your BGP routers, including session status, RIB/FIB contents, and agent health.
I’ll have to make some assumptions about your prior knowledge of Kubernetes, IP networking, and BGP, or this post will be overly long. Remember that if there is anything you’re unclear on, or if I could have done something better, I’m usually available on the Calico Users Slack. It’s a great community where you can learn and contribute. We’d love for you to get involved.
If you want to follow along with this post, you’ll find the resources you need in my GitHub repo calico_cluster_peer_demo. There will be some subtle differences depending on your platform; I won’t attempt to capture all of those here, but again, get in touch and I’d love to chat if you’re working through it.
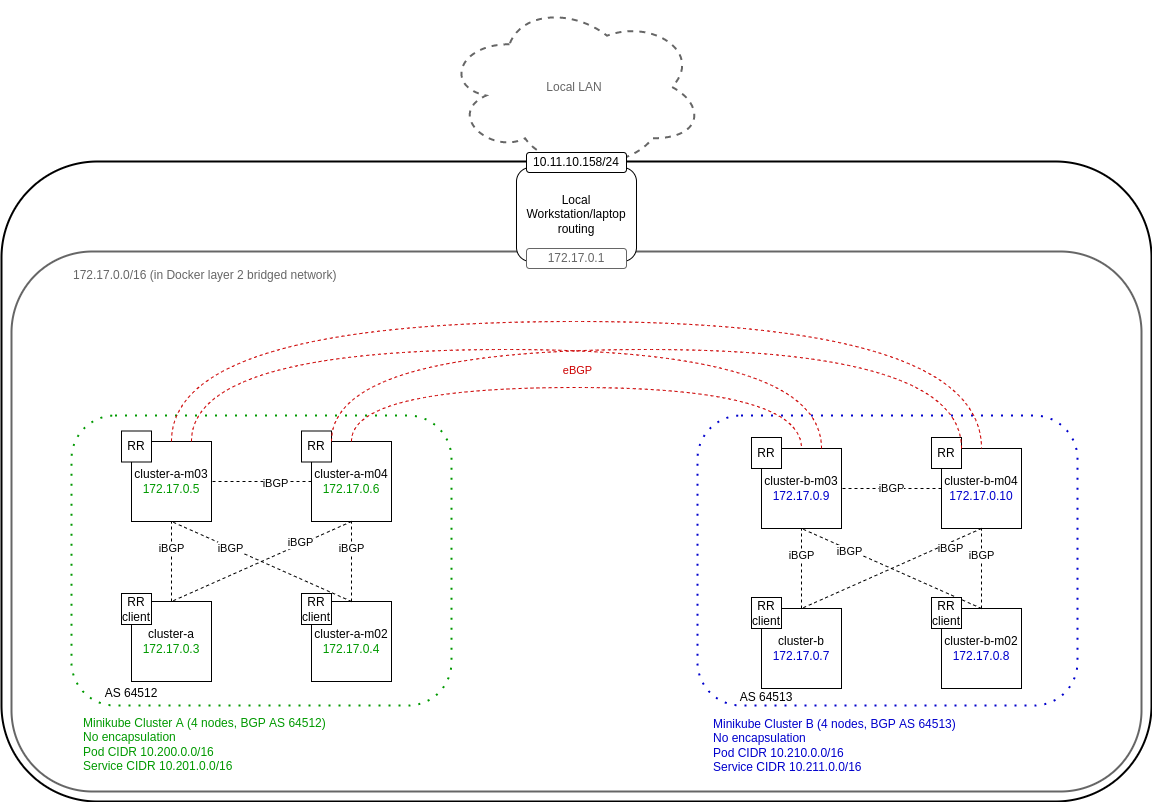
With all that said, here’s what I’ll build. Rather than repeating this diagram throughout the document, I suggest you keep it open in a different tab to refer back to if you’re at all unsure.
Getting Started with a Little Help From the Community
When I started to consider this post, I wanted to avoid using “cheats” or contrived configuration on my local laptop. I wanted the setup to be useful and “vanilla” to the greatest extent possible.
With that in mind, the first challenge I overcame was whether the Minikube networking could be convinced to do what I needed. Minikube is a great tool for running local Kubernetes, focusing on learning and developing for Kubernetes. However, it is not commonly used for advanced CNI (Container Network Interface) configuration testing and modelling.
I wanted to deploy two clusters in Minikube, but by default, Minikube creates a separate Docker layer 2 bridged network for each cluster, something like the diagram below. Please note that this is not the deployment I ended up with —I only include it here to share my learning process.
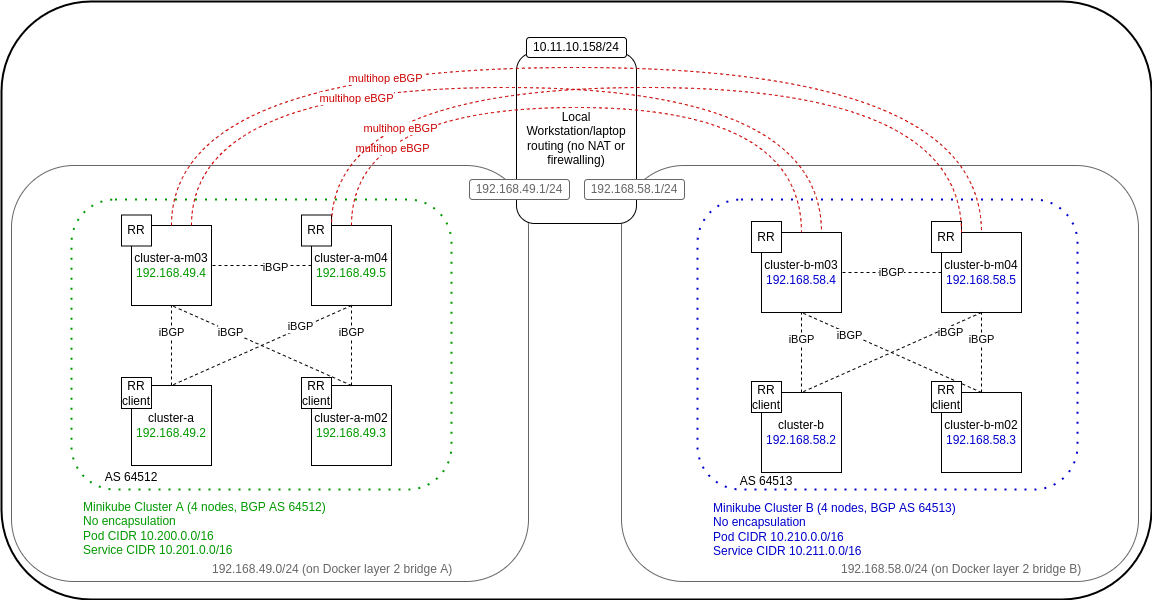
BGP’s transport is just TCP, so in fact the above model is achievable, because BGP’s transport can traverse layer 3 routed boundaries. This is known as multihop BGP. However, the middle “hop,” my local workstation, would either need BGP installed (too fiddly) or static routes to the pod and service networks of each cluster (too contrived). Luckily, multihop BGP is rarely needed for Calico BGP deployments, outside of dual ToR (Top-of-Rack) switch scenarios.
Luckily Minikube’s amazingly helpful community in #minikube on the Kubernetes Slack were incredibly responsive! Medya Ghazizadeh, a Technical Lead Manager at Google, kindly put together this PR that allows Minikube to create two clusters on the same Docker network, as per my original target design. Thanks Medya! If you choose to try to replicate my build, you will need to either use the version of Minikube from the PR or ensure that the changes have been merged into the release version you choose.
Getting Warmed Up: Building the cluster-a Minikube Cluster
Thanks to Medya’s change, it was easy to get started with building two separate Minikube clusters in a single Docker network. If you’re following along, start by backing up any existing kubeconfig file. If you have any existing Minikube clusters, you will probably want to delete them in order to keep a simple setup.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─543─▶ minikube delete --all 🔥 Successfully deleted all profiles
A nice clean slate.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─544─▶ minikube profile list 🤹 Exiting due to MK_USAGE_NO_PROFILE: No minikube profile was found. 💡 Suggestion: You can create one using 'minikube start'.
Start by creating a cluster called cluster-a. We specify the following characteristics:
- No CNI installed
- No static IPs (this allows two clusters in the same subnet)
- A pod CIDR of 10.200.0.0/16
- A service CIDR of 10.201.0.0/16
- Create and use a new Docker network called calico_cluster_peer_demo
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─547─▶ minikube -p cluster-a start --network-plugin=cni --static-ip=false \ --extra-config=kubeadm.pod-network-cidr=10.200.0.0/16 \ --service-cluster-ip-range=10.201.0.0/16 --network=calico_cluster_peer_demo 😄 [cluster-a] minikube v1.24.0 on Ubuntu 20.04 ▪ KUBECONFIG=/home/chris/.kube/config ✨ Automatically selected the docker driver. Other choices: none, ssh ❗ With --network-plugin=cni, you will need to provide your own CNI. See --cni flag as a user-friendly alternative 👍 Starting control plane node cluster-a in cluster cluster-a 🚜 Pulling base image ... 💾 Downloading Kubernetes v1.22.4 preload ... > preloaded-images-k8s-v14-v1...: 501.79 MiB / 501.79 MiB 100.00% 7.80 MiB 🔥 Creating docker container (CPUs=2, Memory=7900MB) ... 🐳 Preparing Kubernetes v1.22.4 on Docker 20.10.8 ... ▪ kubeadm.pod-network-cidr=10.200.0.0/16 ▪ Generating certificates and keys ... ▪ Booting up control plane ... ▪ Configuring RBAC rules ... 🔎 Verifying Kubernetes components... ▪ Using image gcr.io/k8s-minikube/storage-provisioner:v5 🌟 Enabled addons: default-storageclass, storage-provisioner 🏄 Done! kubectl is now configured to use "cluster-a" cluster and "default" namespace by default
At this point, if we examine the Docker networks, the host routing table, and the IP of the new cluster node, we notice something interesting. The new calico_cluster_peer_demo Docker network has been created, but it isn’t actually being used. Instead, the default Docker bridge is being used. This is not a problem for us but it is unintended and has been reported to the Minikube team on the PR noted earlier.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─562─▶ kubectl --cluster=cluster-a get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME cluster-a Ready control-plane,master 7m24s v1.22.4 172.17.0.3 <none> Ubuntu 20.04.2 LTS 5.11.0-41-generic docker://20.10.8 chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─563─▶ route -n | grep 172 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─564─▶ docker network ls NETWORK ID NAME DRIVER SCOPE b3629696615f bridge bridge local 89200de9154e calico_cluster_peer_demo bridge local 8bc049c4e960 host host local 477a1639b48e none null local chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─565─▶ docker network inspect b3629696615f | grep 172 "Subnet": "172.17.0.0/16", "Gateway": "172.17.0.1" "IPv4Address": "172.17.0.3/16",
Next, I install Calico on cluster-a as normal using a tigera-operator installation. I install the latest Tigera operator on the cluster.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─567─▶ kubectl --cluster=cluster-a create -f http://docs.projectcalico.org/manifests/tigera-operator.yaml customresourcedefinition.apiextensions.k8s.io/bgpconfigurations.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/bgppeers.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/blockaffinities.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/caliconodestatuses.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/clusterinformations.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/felixconfigurations.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/globalnetworkpolicies.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/globalnetworksets.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/hostendpoints.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/ipamblocks.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/ipamconfigs.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/ipamhandles.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/ippools.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/ipreservations.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/kubecontrollersconfigurations.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/networkpolicies.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/networksets.crd.projectcalico.org created customresourcedefinition.apiextensions.k8s.io/apiservers.operator.www.tigera.io created customresourcedefinition.apiextensions.k8s.io/imagesets.operator.www.tigera.io created customresourcedefinition.apiextensions.k8s.io/installations.operator.www.tigera.io created customresourcedefinition.apiextensions.k8s.io/tigerastatuses.operator.www.tigera.io created namespace/tigera-operator created Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+ podsecuritypolicy.policy/tigera-operator created serviceaccount/tigera-operator created clusterrole.rbac.authorization.k8s.io/tigera-operator created clusterrolebinding.rbac.authorization.k8s.io/tigera-operator created deployment.apps/tigera-operator created
Then, I provide a manifest for the operator specifying the desired pod CIDR and that I want encapsulation to be disabled. Encapsulation is not required in this environment because all routers involved have a full view of the routing topology (thanks to BGP). After waiting for a short time, we can see that calico-node and the other Calico components have been installed by the operator and are running as intended.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─568─▶ cat cluster_a_calicomanifests/custom-resources.yaml
# This section includes base Calico installation configuration.
# For more information, see: http://docs.projectcalico.org/v3.21/reference/installation/api#operator.www.tigera.io/v1.Installation
apiVersion: operator.www.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
# Configures Calico networking.
calicoNetwork:
# Note: The ipPools section cannot be modified post-install.
ipPools:
- blockSize: 26
cidr: 10.200.0.0/16
encapsulation: None
natOutgoing: Enabled
nodeSelector: all()
---
# This section configures the Calico API server.
# For more information, see: http://docs.projectcalico.org/v3.21/reference/installation/api#operator.www.tigera.io/v1.APIServer
apiVersion: operator.www.tigera.io/v1
kind: APIServer
metadata:
name: default
spec: {}
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─569─▶ kubectl --cluster=cluster-a create -f cluster_a_calicomanifests/custom-resources.yaml
installation.operator.www.tigera.io/default created
apiserver.operator.www.tigera.io/default created
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─572─▶ kubectl --cluster=cluster-a get pods -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-system calico-kube-controllers-77f7ccd674-zc57c 1/1 Running 0 73s 10.200.97.1 cluster-a <none> <none>
calico-system calico-node-d769d 1/1 Running 0 73s 172.17.0.3 cluster-a <none> <none>
calico-system calico-typha-85cdb594bc-xh8m9 1/1 Running 0 73s 172.17.0.3 cluster-a <none> <none>
kube-system coredns-78fcd69978-8ghx6 1/1 Running 0 76m 10.200.97.0 cluster-a <none> <none>
kube-system etcd-cluster-a 1/1 Running 0 76m 172.17.0.3 cluster-a <none> <none>
kube-system kube-apiserver-cluster-a 1/1 Running 0 76m 172.17.0.3 cluster-a <none> <none>
kube-system kube-controller-manager-cluster-a 1/1 Running 0 76m 172.17.0.3 cluster-a <none> <none>
kube-system kube-proxy-zpdpg 1/1 Running 0 76m 172.17.0.3 cluster-a <none> <none>
kube-system kube-scheduler-cluster-a 1/1 Running 0 76m 172.17.0.3 cluster-a <none> <none>
kube-system storage-provisioner 1/1 Running 1 (75m ago) 76m 172.17.0.3 cluster-a <none> <none>
tigera-operator tigera-operator-b78466769-gmznr 1/1 Running 0 2m2s 172.17.0.3 cluster-a <none> <none>
At the moment, the cluster only has one node. Since this is Minikube, there is no taint on the master node and I can therefore deploy the testing workload that I will use later to show that things are working. It is James Harris’s echo-server. You can see the license in the GitHub repo here.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─572─▶ kubectl --cluster=cluster-a apply -f testingworkload/echo-server.yaml deployment.apps/echoserver created service/echoserver-external created chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─573─▶ kubectl --cluster=cluster-a get pods NAME READY STATUS RESTARTS AGE echoserver-6558697d87-2j56w 1/1 Running 0 13s
Now I’ll add 3 more nodes to the cluster so there are 4, as shown in the diagram.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─577─▶ for i in {1..3}; do minikube --profile cluster-a node add; done
😄 Adding node m02 to cluster cluster-a
❗ Cluster was created without any CNI, adding a node to it might cause broken networking.
👍 Starting worker node cluster-a-m02 in cluster cluster-a
🚜 Pulling base image ...
🔥 Creating docker container (CPUs=2, Memory=2200MB) ...
🐳 Preparing Kubernetes v1.22.4 on Docker 20.10.8 ...
🔎 Verifying Kubernetes components...
🏄 Successfully added m02 to cluster-a!
😄 Adding node m03 to cluster cluster-a
👍 Starting worker node cluster-a-m03 in cluster cluster-a
🚜 Pulling base image ...
🔥 Creating docker container (CPUs=2, Memory=2200MB) ...
❗ This container is having trouble accessing http://k8s.gcr.io
💡 To pull new external images, you may need to configure a proxy: http://minikube.sigs.k8s.io/docs/reference/networking/proxy/
🐳 Preparing Kubernetes v1.22.4 on Docker 20.10.8 ...
🔎 Verifying Kubernetes components...
🏄 Successfully added m03 to cluster-a!
😄 Adding node m04 to cluster cluster-a
👍 Starting worker node cluster-a-m04 in cluster cluster-a
🚜 Pulling base image ...
🔥 Creating docker container (CPUs=2, Memory=2200MB) ...
🐳 Preparing Kubernetes v1.22.4 on Docker 20.10.8 ...
🔎 Verifying Kubernetes components...
🏄 Successfully added m04 to cluster-a!
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─578─▶ kubectl --cluster=cluster-a get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
cluster-a Ready control-plane,master 85m v1.22.4 172.17.0.3 <none> Ubuntu 20.04.2 LTS 5.11.0-41-generic docker://20.10.8
cluster-a-m02 Ready <none> 75s v1.22.4 172.17.0.4 <none> Ubuntu 20.04.2 LTS 5.11.0-41-generic docker://20.10.8
cluster-a-m03 Ready <none> 57s v1.22.4 172.17.0.5 <none> Ubuntu 20.04.2 LTS 5.11.0-41-generic docker://20.10.8
cluster-a-m04 Ready <none> 43s v1.22.4 172.17.0.6 <none> Ubuntu 20.04.2 LTS 5.11.0-41-generic docker://20.10.8
minikube node add erroneously adds kindnet as a side-effect, so we remove that as we already have Calico as a CNI.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─581─▶ kubectl --cluster=cluster-a get pods -A -o wide | grep -i kindnet kube-system kindnet-5s6nf 1/1 Running 0 111s 172.17.0.6 cluster-a-m04 <none> <none> kube-system kindnet-nm62s 1/1 Running 0 2m18s 172.17.0.3 cluster-a <none> <none> kube-system kindnet-twz2j 1/1 Running 0 2m18s 172.17.0.4 cluster-a-m02 <none> <none> kube-system kindnet-v7rsj 1/1 Running 0 2m5s 172.17.0.5 cluster-a-m03 <none> <none> chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─582─▶ kubectl --cluster=cluster-a delete ds -n=kube-system kindnet daemonset.apps "kindnet" deleted
Now I’ll download and install the calicoctl binary in /usr/local/bin on the 4 cluster nodes, and then run it on all of them by SSHing into them and issuing sudo calicoctl node status. This is a quick way of showing the state of BGP peerings on the cluster. In a follow-on blog post, I will show you how to do this, and many other things, with the new CalicoNodeStatus API, but I prefer to capture all of that knowledge in a single post. So, for now:
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─588─▶ for i in cluster-a cluster-a-m02 cluster-a-m03 cluster-a-m04; do minikube ssh -p cluster-a -n $i "curl -o calicoctl -O -L http://github.com/projectcalico/calicoctl/releases/download/v3.21.1/calicoctl && sudo mv calicoctl /usr/local/bin/calicoctl && chmod +x /usr/local/bin/calicoctl"; done % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 615 100 615 0 0 2460 0 --:--:-- --:--:-- --:--:-- 2469 100 42.0M 100 42.0M 0 0 7452k 0 0:00:05 0:00:05 --:--:-- 8294k % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 615 100 615 0 0 7884 0 --:--:-- --:--:-- --:--:-- 7884 100 42.0M 100 42.0M 0 0 8111k 0 0:00:05 0:00:05 --:--:-- 8306k % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 615 100 615 0 0 6340 0 --:--:-- --:--:-- --:--:-- 6406 100 42.0M 100 42.0M 0 0 8139k 0 0:00:05 0:00:05 --:--:-- 8471k % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 615 100 615 0 0 6612 0 --:--:-- --:--:-- --:--:-- 6612 100 42.0M 100 42.0M 0 0 8016k 0 0:00:05 0:00:05 --:--:-- 8355k chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─589─▶ for i in cluster-a cluster-a-m02 cluster-a-m03 cluster-a-m04; do minikube ssh -p cluster-a -n $i "sudo calicoctl node status"; done Calico process is running. IPv4 BGP status +--------------+-------------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +--------------+-------------------+-------+----------+-------------+ | 172.17.0.4 | node-to-node mesh | up | 13:44:11 | Established | | 172.17.0.5 | node-to-node mesh | up | 13:44:46 | Established | | 172.17.0.6 | node-to-node mesh | up | 13:44:52 | Established | +--------------+-------------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found. Calico process is running. IPv4 BGP status +--------------+-------------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +--------------+-------------------+-------+----------+-------------+ | 172.17.0.3 | node-to-node mesh | up | 13:44:11 | Established | | 172.17.0.5 | node-to-node mesh | up | 13:44:46 | Established | | 172.17.0.6 | node-to-node mesh | up | 13:44:52 | Established | +--------------+-------------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found. Calico process is running. IPv4 BGP status +--------------+-------------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +--------------+-------------------+-------+----------+-------------+ | 172.17.0.3 | node-to-node mesh | up | 13:44:47 | Established | | 172.17.0.4 | node-to-node mesh | up | 13:44:47 | Established | | 172.17.0.6 | node-to-node mesh | up | 13:44:53 | Established | +--------------+-------------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found. Calico process is running. IPv4 BGP status +--------------+-------------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +--------------+-------------------+-------+----------+-------------+ | 172.17.0.3 | node-to-node mesh | up | 13:44:53 | Established | | 172.17.0.4 | node-to-node mesh | up | 13:44:53 | Established | | 172.17.0.5 | node-to-node mesh | up | 13:44:53 | Established | +--------------+-------------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found.
Before we move on, it’s worth taking a moment to notice the default state of BGP on a fresh cluster installed with the Tigera operator and encapsulation disabled. Although the user does not need to be aware of it at this point, BGP is already running and:
- The BGP is using the default port, TCP/179
- The nodes are in an iBGP full mesh (each node is BGP peered to every other node)
- All nodes are all in the same BGP AS, 64512 (which is what makes this iBGP, not eBGP—the i stands for “Internal”)
It is outside of the scope of this post to give full details, but to simplify: for now, a full mesh is required because iBGP has a routing loop prevention mechanism that means all nodes must peer directly or they will not have a view of all routes in the AS.
If the peers are not “Established,” it is often the case that TCP/179 is being blocked by the underlying network.
I know that, at this point, those with some experience of routing protocols might become nervous seeing BGP running already. That’s because many well known routing protocols, such as OSPF, have a discovery mechanism that means they start peering and exchanging routes with any and all routers they find nearby.
That is not the case with vanilla BGP, so you don’t need to be concerned—neighbors are added explicitly by IP and port. In addition, it’s possible to add a BGP password, both for additional security and peace of mind.
By examining the nodes, pods, and services, we can see that cluster-a appears healthy.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─591─▶ kubectl --cluster=cluster-a get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME cluster-a Ready control-plane,master 107m v1.22.4 172.17.0.3 <none> Ubuntu 20.04.2 LTS 5.11.0-41-generic docker://20.10.8 cluster-a-m02 Ready <none> 23m v1.22.4 172.17.0.4 <none> Ubuntu 20.04.2 LTS 5.11.0-41-generic docker://20.10.8 cluster-a-m03 Ready <none> 23m v1.22.4 172.17.0.5 <none> Ubuntu 20.04.2 LTS 5.11.0-41-generic docker://20.10.8 cluster-a-m04 Ready <none> 22m v1.22.4 172.17.0.6 <none> Ubuntu 20.04.2 LTS 5.11.0-41-generic docker://20.10.8 chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─592─▶ kubectl --cluster=cluster-a get pods -A -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES calico-apiserver calico-apiserver-6b6fbf66fc-m5dm6 1/1 Running 0 30m 10.200.97.4 cluster-a <none> <none> calico-apiserver calico-apiserver-6b6fbf66fc-wwrg9 1/1 Running 0 30m 10.200.97.5 cluster-a <none> <none> calico-system calico-kube-controllers-77f7ccd674-zc57c 1/1 Running 0 32m 10.200.97.1 cluster-a <none> <none> calico-system calico-node-d769d 1/1 Running 0 32m 172.17.0.3 cluster-a <none> <none> calico-system calico-node-f8zfc 1/1 Running 0 23m 172.17.0.5 cluster-a-m03 <none> <none> calico-system calico-node-lz6vf 1/1 Running 0 22m 172.17.0.6 cluster-a-m04 <none> <none> calico-system calico-node-vpdp2 1/1 Running 0 23m 172.17.0.4 cluster-a-m02 <none> <none> calico-system calico-typha-85cdb594bc-646fb 1/1 Running 0 23m 172.17.0.5 cluster-a-m03 <none> <none> calico-system calico-typha-85cdb594bc-xh8m9 1/1 Running 0 32m 172.17.0.3 cluster-a <none> <none> default echoserver-6558697d87-2j56w 1/1 Running 0 28m 10.200.97.6 cluster-a <none> <none> kube-system coredns-78fcd69978-8ghx6 1/1 Running 0 107m 10.200.97.0 cluster-a <none> <none> kube-system etcd-cluster-a 1/1 Running 0 107m 172.17.0.3 cluster-a <none> <none> kube-system kube-apiserver-cluster-a 1/1 Running 0 107m 172.17.0.3 cluster-a <none> <none> kube-system kube-controller-manager-cluster-a 1/1 Running 0 107m 172.17.0.3 cluster-a <none> <none> kube-system kube-proxy-bl5db 1/1 Running 0 22m 172.17.0.6 cluster-a-m04 <none> <none> kube-system kube-proxy-ljdwm 1/1 Running 0 23m 172.17.0.5 cluster-a-m03 <none> <none> kube-system kube-proxy-r86h9 1/1 Running 0 23m 172.17.0.4 cluster-a-m02 <none> <none> kube-system kube-proxy-zpdpg 1/1 Running 0 107m 172.17.0.3 cluster-a <none> <none> kube-system kube-scheduler-cluster-a 1/1 Running 0 107m 172.17.0.3 cluster-a <none> <none> kube-system storage-provisioner 1/1 Running 1 (106m ago) 107m 172.17.0.3 cluster-a <none> <none> tigera-operator tigera-operator-b78466769-gmznr 1/1 Running 0 32m 172.17.0.3 cluster-a <none> <none> chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─593─▶ kubectl --cluster=cluster-a get services -A -o wide NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR calico-apiserver calico-api ClusterIP 10.201.214.10 <none> 443/TCP 30m apiserver=true calico-system calico-kube-controllers-metrics ClusterIP 10.201.87.46 <none> 9094/TCP 31m k8s-app=calico-kube-controllers calico-system calico-typha ClusterIP 10.201.184.6 <none> 5473/TCP 32m k8s-app=calico-typha default echoserver-external LoadBalancer 10.201.15.6 <pending> 8385:32423/TCP 28m app=echoserver default kubernetes ClusterIP 10.201.0.1 <none> 443/TCP 107m <none> kube-system kube-dns ClusterIP 10.201.0.10 <none> 53/UDP,53/TCP,9153/TCP 107m k8s-app=kube-dns
One cluster done, one to go!
Up to Speed: Building the cluster-b Minikube Cluster in the same Docker Network
In the interests of finishing this blog post before your next birthday, we won’t repeat the output of all those steps here for cluster-b. The process is exactly the same, except that the pod CIDR is now 10.210.0.0/16 and the service CIDR is now 10.211.0.0/16.
Note that for now, this new cluster will have the same BGP AS as cluster-a. Later, I’ll change that. For now though, notice that it is not an issue for two BGP clusters to be using the same AS, provided that they are not intentionally BGP peering with each other (or misconfigured to do so).
Here are the commands I ran to build and validate the cluster, just like cluster-a above.
# Build
minikube -p cluster-b start --network-plugin=cni --static-ip=false \
--extra-config=kubeadm.pod-network-cidr=10.210.0.0/16 \
--service-cluster-ip-range=10.211.0.0/16 --network=calico_cluster_peer_demo
kubectl --cluster=cluster-b create -f http://docs.projectcalico.org/manifests/tigera-operator.yaml
kubectl --cluster=cluster-b create -f cluster_b_calicomanifests/custom-resources.yaml
kubectl --cluster=cluster-b apply -f testingworkload/echo-server.yaml
for i in {1..3}; do minikube --profile cluster-b node add; done
kubectl --cluster=cluster-b delete ds -n=kube-system kindnet
for i in cluster-b cluster-b-m02 cluster-b-m03 cluster-b-m04; do minikube ssh -p cluster-b -n $i "curl -o calicoctl -O -L http://github.com/projectcalico/calicoctl/releases/download/v3.21.1/calicoctl && sudo mv calicoctl /usr/local/bin/calicoctl && chmod +x /usr/local/bin/calicoctl"; done
# Validate
for i in cluster-b cluster-b-m02 cluster-b-m03 cluster-b-m04; do minikube ssh -p cluster-b -n $i "sudo calicoctl node status"; done
kubectl --cluster=cluster-b get nodes -o wide
kubectl --cluster=cluster-b get pods -A -o wide
kubectl --cluster=cluster-b get services -A -o wide
Great! Now I’ll get the clusters peering with each other, and explain some subtleties of BGP as I go along.
Converting the Clusters to a New Deployment Model
As per the original design, my aim is not to have one big cluster of eight nodes. I want to have two clusters of four nodes. So, the first step is to switch cluster-b to use BGP AS 64513. Nothing else will change. Since all 4 nodes in cluster-b will switch to the new AS, cluster-b will continue to use iBGP and everything else will remain unchanged. There will be a very brief traffic interruption (sub-second) as the AS is changed.
I will also tell both clusters to advertise their service CIDR block.
As is usually the case with well-designed Kubernetes tools, changing the BGP AS is not done directly on the nodes. Instead it is applied as YAML that is noticed by the calico-node pod running on every node.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─613─▶ cat cluster_a_calicomanifests/bgp-configuration.yaml apiVersion: projectcalico.org/v3 kind: BGPConfiguration metadata: name: default spec: asNumber: 64512 listenPort: 179 logSeverityScreen: Info nodeToNodeMeshEnabled: true serviceClusterIPs: - cidr: 10.201.0.0/16 chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─614─▶ cat cluster_b_calicomanifests/bgp-configuration.yaml apiVersion: projectcalico.org/v3 kind: BGPConfiguration metadata: name: default spec: asNumber: 64513 listenPort: 179 logSeverityScreen: Info nodeToNodeMeshEnabled: true serviceClusterIPs: - cidr: 10.211.0.0/16 chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─615─▶ kubectl config use-context cluster-a && calicoctl apply -f cluster_a_calicomanifests/bgp-configuration.yaml Switched to context "cluster-a". Successfully applied 1 'BGPConfiguration' resource(s) chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─616─▶ kubectl config use-context cluster-b && calicoctl apply -f cluster_b_calicomanifests/bgp-configuration.yaml Switched to context "cluster-b". Successfully applied 1 'BGPConfiguration' resource(s)
cluster-b is now running on BGP AS 64513, and both clusters are advertising their service CIDR IP range and pod CIDR IP ranges, which are unique. That’s it, right? The next step is to peer them together?
Well, yes and no.
It would be possible to peer the clusters directly to each other. However, which nodes in each cluster would need to peer? Since Kubernetes cluster nodes can come and go depending on requirements, it would be difficult to choose which nodes to peer, and peering all of them would be unwieldy and inefficient.
Instead, I’ll show you how to do this in a more predictable and scalable way.
Route Reflectors for Fun and Profit
iBGP route reflectors (from now on, I’ll refer to them as “RRs”) are conceptually not that complex. For the purposes of this post, you can just be aware that they act like normal iBGP nodes, except that they:
Are allowed to forward routes they learn from one iBGP peer to another
Can be clustered to facilitate high-availability configurations
In short, this means that a BGP AS where iBGP RRs are configured no longer needs to maintain a full mesh. It is sufficient for all non-RR BGP nodes to peer only with the RRs. The RRs, in turn, must still peer with all other nodes, including other RRs in the RR cluster.
This is beneficial for our setup. Now, no matter how many Kubernetes nodes are added to either cluster, the BGP peerings will not need to be adjusted! The peerings in each cluster will be automatically adjusted by Calico based on Kubernetes labels.
In addition, four eBGP (External BGP) peerings between the two clusters will be added to allow each cluster to advertise its pod and service CIDR to the other cluster, resulting in end-to-end reachability without any NAT or encapsulation. Since the route reflectors are predefined and static, and there are two in each cluster, this configuration won’t need altering once the clusters are up and running.
Each cluster has four nodes. The following nodes will be route reflectors and eBGP peers, as shown in the diagram:
- cluster-a-m03
- cluster-a-m04
- cluster-b-m03
- cluster-a-m04
All other nodes will be normal iBGP peers only.
Let’s get started!
Building the final BGP Configuration
First, I will drain all workloads off the nodes that will become RRs. There is no need to worry about DaemonSet-managed pods—those will sort themselves out. Similarly, other workloads that require a certain number of replicas, such as calico-apiserver, will re-establish their target if necessary. That’s why the output below shows one of the calico-apiserver pods as only having been running for a short period of time.
Draining workloads from these nodes will ensure that disruption is minimal when BGP reconverges, though in this lab that doesn’t really matter.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─617─▶ kubectl --cluster=cluster-a drain --ignore-daemonsets cluster-a-m03 cluster-a-m04 node/cluster-a-m03 cordoned node/cluster-a-m04 cordoned WARNING: ignoring DaemonSet-managed Pods: calico-system/calico-node-f8zfc, kube-system/kube-proxy-ljdwm evicting pod calico-system/calico-typha-85cdb594bc-646fb pod/calico-typha-85cdb594bc-646fb evicted node/cluster-a-m03 evicted WARNING: ignoring DaemonSet-managed Pods: calico-system/calico-node-lz6vf, kube-system/kube-proxy-bl5db node/cluster-a-m04 evicted chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─618─▶ kubectl --cluster=cluster-b drain --ignore-daemonsets cluster-b-m03 cluster-b-m04 node/cluster-b-m03 cordoned node/cluster-b-m04 cordoned WARNING: ignoring DaemonSet-managed Pods: calico-system/calico-node-lhd2m, kube-system/kube-proxy-vq59b evicting pod calico-system/calico-typha-77f8864c6b-bv6nd pod/calico-typha-77f8864c6b-bv6nd evicted node/cluster-b-m03 evicted WARNING: ignoring DaemonSet-managed Pods: calico-system/calico-node-h4twg, kube-system/kube-proxy-gtvnp evicting pod calico-apiserver/calico-apiserver-7f7dcc9d58-wltf6 pod/calico-apiserver-7f7dcc9d58-wltf6 evicted node/cluster-b-m04 evicted chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─619─▶ kubectl --cluster=cluster-b get pods -A -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES calico-apiserver calico-apiserver-7f7dcc9d58-59lkg 1/1 Running 0 110m 10.210.74.1 cluster-b-m02 <none> <none> calico-apiserver calico-apiserver-7f7dcc9d58-5lsfb 1/1 Running 0 68s 10.210.139.131 cluster-b <none> <none> calico-system calico-kube-controllers-557c85c64f-xjllh 1/1 Running 0 113m 10.210.139.130 cluster-b <none> <none> calico-system calico-node-9pbcq 1/1 Running 0 113m 172.17.0.7 cluster-b <none> <none> calico-system calico-node-bxqrp 1/1 Running 0 113m 172.17.0.8 cluster-b-m02 <none> <none> calico-system calico-node-h4twg 1/1 Running 0 112m 172.17.0.10 cluster-b-m04 <none> <none> calico-system calico-node-lhd2m 1/1 Running 0 113m 172.17.0.9 cluster-b-m03 <none> <none> calico-system calico-typha-77f8864c6b-gnpzr 1/1 Running 0 113m 172.17.0.7 cluster-b <none> <none> default echoserver-6558697d87-9tl8b 1/1 Running 0 113m 10.210.139.128 cluster-b <none> <none> kube-system coredns-78fcd69978-mn7t6 1/1 Running 0 120m 10.210.139.129 cluster-b <none> <none> kube-system etcd-cluster-b 1/1 Running 0 121m 172.17.0.7 cluster-b <none> <none> kube-system kube-apiserver-cluster-b 1/1 Running 0 121m 172.17.0.7 cluster-b <none> <none> kube-system kube-controller-manager-cluster-b 1/1 Running 0 121m 172.17.0.7 cluster-b <none> <none> kube-system kube-proxy-2wt65 1/1 Running 0 113m 172.17.0.8 cluster-b-m02 <none> <none> kube-system kube-proxy-gtvnp 1/1 Running 0 112m 172.17.0.10 cluster-b-m04 <none> <none> kube-system kube-proxy-jv9df 1/1 Running 0 120m 172.17.0.7 cluster-b <none> <none> kube-system kube-proxy-vq59b 1/1 Running 0 113m 172.17.0.9 cluster-b-m03 <none> <none> kube-system kube-scheduler-cluster-b 1/1 Running 0 121m 172.17.0.7 cluster-b <none> <none> kube-system storage-provisioner 1/1 Running 1 (120m ago) 121m 172.17.0.7 cluster-b <none> <none> tigera-operator tigera-operator-b78466769-vr2x4 1/1 Running 0 120m 172.17.0.7 cluster-b <none> <none>
Next, it’s time to instruct Calico to make the target nodes RRs, by patching their node configurations with a route reflector cluster ID. Note that this is the same across both RRs in each cluster, but different across clusters. Actually, it could be the same in each cluster, but it felt prudent to make it different.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─620─▶ kubectl config use-context cluster-a && calicoctl patch node cluster-a-m03 -p '{"spec": {"bgp": {"routeReflectorClusterID": "244.0.0.1"}}}' && calicoctl patch node cluster-a-m04 -p '{"spec": {"bgp": {"routeReflectorClusterID": "244.0.0.1"}}}'
Switched to context "cluster-a".
Successfully patched 1 'Node' resource
Successfully patched 1 'Node' resource
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─621─▶ kubectl config use-context cluster-b && calicoctl patch node cluster-b-m03 -p '{"spec": {"bgp": {"routeReflectorClusterID": "244.0.0.2"}}}' && calicoctl patch node cluster-b-m04 -p '{"spec": {"bgp": {"routeReflectorClusterID": "244.0.0.2"}}}'
Switched to context "cluster-b".
Successfully patched 1 'Node' resource
Successfully patched 1 'Node' resource
Now, I’ll apply a route-reflector=true Kubernetes label to the nodes that are now RRs, and then I’ll apply a manifest in both clusters instructing all nodes to establish a BGP peering with any node with that label. Finally, I’ll disable the automatic full mesh that we saw at the start of this blog post. You can think of that as removing the “scaffolding” now that we have set up this new BGP configuration.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─623─▶ kubectl --cluster=cluster-a label node cluster-a-m03 route-reflector=true
node/cluster-a-m03 labeled
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─624─▶ kubectl --cluster=cluster-a label node cluster-a-m04 route-reflector=true
node/cluster-a-m04 labeled
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─625─▶ kubectl --cluster=cluster-b label node cluster-b-m03 route-reflector=true
node/cluster-b-m03 labeled
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─626─▶ kubectl --cluster=cluster-b label node cluster-b-m04 route-reflector=true
node/cluster-b-m04 labeled
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─627─▶ cat cluster_a_calicomanifests/bgp-rr-configuration.yaml
kind: BGPPeer
apiVersion: projectcalico.org/v3
metadata:
name: peer-with-route-reflectors
spec:
nodeSelector: all()
peerSelector: route-reflector == 'true'
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─628─▶ cat cluster_b_calicomanifests/bgp-rr-configuration.yaml
kind: BGPPeer
apiVersion: projectcalico.org/v3
metadata:
name: peer-with-route-reflectors
spec:
nodeSelector: all()
peerSelector: route-reflector == 'true'
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─629─▶ kubectl config use-context cluster-a && calicoctl apply -f cluster_a_calicomanifests/bgp-rr-configuration.yaml
Switched to context "cluster-a".
Successfully applied 1 'BGPPeer' resource(s)
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─630─▶ kubectl config use-context cluster-b && calicoctl apply -f cluster_b_calicomanifests/bgp-rr-configuration.yaml
Switched to context "cluster-b".
Successfully applied 1 'BGPPeer' resource(s)
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─631─▶ kubectl config use-context cluster-a && calicoctl patch bgpconfiguration default -p '{"spec": {"nodeToNodeMeshEnabled": false}}'
Switched to context "cluster-a".
Successfully patched 1 'BGPConfiguration' resource
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─632─▶
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main]
└─632─▶ kubectl config use-context cluster-b && calicoctl patch bgpconfiguration default -p '{"spec": {"nodeToNodeMeshEnabled": false}}'
Switched to context "cluster-b".
Successfully patched 1 'BGPConfiguration' resource
To keep this blog from becoming absurdly long, I won’t show the output here, but if you were to check the BGP status again as you did earlier, you would see that in each cluster, the BGP is as we described before: the RR nodes are peered to all other nodes, and the non-RR nodes are peered only to the RRs.
Let’s uncordon those RRs now to allow them to carry workloads again.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─634─▶ kubectl --cluster=cluster-a uncordon cluster-a-m03 cluster-a-m04 node/cluster-a-m03 uncordoned node/cluster-a-m04 uncordoned chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─635─▶ kubectl --cluster=cluster-b uncordon cluster-b-m03 cluster-b-m04 node/cluster-b-m03 uncordoned node/cluster-b-m04 uncordoned
It’s time to establish the eBGP peerings between the clusters now. We manually instruct each RR node to eBGP peer with the two RR nodes in the other cluster. As we noted before, this will not need any further adjustment if we add more nodes to the cluster.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─636─▶ cat cluster_a_calicomanifests/bgp-other-cluster.yaml apiVersion: projectcalico.org/v3 kind: BGPPeer metadata: name: cluster-b-m03 spec: asNumber: 64513 nodeSelector: route-reflector == 'true' peerIP: 172.17.0.9 --- apiVersion: projectcalico.org/v3 kind: BGPPeer metadata: name: cluster-b-m04 spec: asNumber: 64513 nodeSelector: route-reflector == 'true' peerIP: 172.17.0.10 chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─637─▶ cat cluster_b_calicomanifests/bgp-other-cluster.yaml apiVersion: projectcalico.org/v3 kind: BGPPeer metadata: name: cluster-a-m03 spec: asNumber: 64512 nodeSelector: route-reflector == 'true' peerIP: 172.17.0.5 --- apiVersion: projectcalico.org/v3 kind: BGPPeer metadata: name: cluster-a-m04 spec: asNumber: 64512 nodeSelector: route-reflector == 'true' peerIP: 172.17.0.6 chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─638─▶ kubectl config use-context cluster-a && calicoctl apply -f cluster_a_calicomanifests/bgp-other-cluster.yaml Switched to context "cluster-a". Successfully applied 2 'BGPPeer' resource(s) chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─639─▶ kubectl config use-context cluster-b && calicoctl apply -f cluster_b_calicomanifests/bgp-other-cluster.yaml Switched to context "cluster-b". Successfully applied 2 'BGPPeer' resource(s)
It would be reasonable to expect everything to be working at this point, but there is still one more thing to do.
In any good BGP network, including a Calico cluster that is running BGP, route advertisement filtering is implemented between all BGP peers to ensure that only the route advertisements that are expected and intended are allowed to propagate. This is normal behavior in a BGP network—it can be considered a “belt-and-braces” way of making sure that routing is working in the way that was intended.
It is quite an unusual use case to peer two clusters directly in the way that we are doing in this blog. Calico’s BGP is more commonly used to peer with Top-of-Rack switches. In that scenario, receiving a default route from the ToR is usually adequate; it is not necessary for Calico to accept more granular/specific routes. Calico’s default BGP behavior disallows these more granular routes from being advertised further within each cluster.
Never fear. I haven’t come this far to give up! Luckily, it’s easy to alter the behavior so that both clusters accept the more granular routes. I do this by creating IPPool resources in both clusters that are in a disabled state. Each cluster’s new pools are configured with the CIDR addresses of the other cluster’s service and pod CIDRs. The result of doing this is that both clusters alter their behavior and accept them, since the IPs are now recognized. Since the IP pools are created in a disabled state, the IPs won’t actually be assigned to pods on the wrong cluster—only recognized.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─641─▶ cat cluster_a_calicomanifests/disabled-othercluster-ippools.yaml apiVersion: projectcalico.org/v3 kind: IPPool metadata: name: disabled-podcidr-for-clusterb spec: cidr: 10.210.0.0/16 disabled: true natOutgoing: false --- apiVersion: projectcalico.org/v3 kind: IPPool metadata: name: disabled-servicecidr-for-clusterb spec: cidr: 10.211.0.0/16 disabled: true natOutgoing: false chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─642─▶ cat cluster_b_calicomanifests/disabled-othercluster-ippools.yaml apiVersion: projectcalico.org/v3 kind: IPPool metadata: name: disabled-podcidr-for-clustera spec: cidr: 10.200.0.0/16 disabled: true natOutgoing: false --- apiVersion: projectcalico.org/v3 kind: IPPool metadata: name: disabled-servicecidr-for-clustera spec: cidr: 10.201.0.0/16 disabled: true natOutgoing: false chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─643─▶ kubectl config use-context cluster-a && calicoctl apply -f cluster_a_calicomanifests/disabled-othercluster-ippools.yaml Switched to context "cluster-a". Successfully applied 2 'IPPool' resource(s) chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─644─▶ kubectl config use-context cluster-b && calicoctl apply -f cluster_b_calicomanifests/disabled-othercluster-ippools.yaml Switched to context "cluster-b". Successfully applied 2 'IPPool' resource(s)
That’s it! Everything is done. Let’s do some testing and prove that things are working as intended.
End-to-End Validation
As noted earlier, we’ll revisit this setup to demonstrate other Calico features in later blog posts. For now, all that remains is to show that everything is working as expected and matches the diagram from earlier.
So, first of all I will show the nodes, pods, and services from cluster-a.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─649─▶ kubectl --cluster=cluster-a get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME cluster-a Ready control-plane,master 6h10m v1.22.4 172.17.0.3 <none> Ubuntu 20.04.2 LTS 5.11.0-41-generic docker://20.10.8 cluster-a-m02 Ready <none> 4h46m v1.22.4 172.17.0.4 <none> Ubuntu 20.04.2 LTS 5.11.0-41-generic docker://20.10.8 cluster-a-m03 Ready <none> 4h45m v1.22.4 172.17.0.5 <none> Ubuntu 20.04.2 LTS 5.11.0-41-generic docker://20.10.8 cluster-a-m04 Ready <none> 4h45m v1.22.4 172.17.0.6 <none> Ubuntu 20.04.2 LTS 5.11.0-41-generic docker://20.10.8 chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─650─▶ kubectl --cluster=cluster-a get pods -A -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES calico-apiserver calico-apiserver-6b6fbf66fc-m5dm6 1/1 Running 0 4h53m 10.200.97.4 cluster-a <none> <none> calico-apiserver calico-apiserver-6b6fbf66fc-wwrg9 1/1 Running 0 4h53m 10.200.97.5 cluster-a <none> <none> calico-system calico-kube-controllers-77f7ccd674-zc57c 1/1 Running 0 4h55m 10.200.97.1 cluster-a <none> <none> calico-system calico-node-d769d 1/1 Running 0 4h55m 172.17.0.3 cluster-a <none> <none> calico-system calico-node-f8zfc 1/1 Running 0 4h45m 172.17.0.5 cluster-a-m03 <none> <none> calico-system calico-node-lz6vf 1/1 Running 0 4h45m 172.17.0.6 cluster-a-m04 <none> <none> calico-system calico-node-vpdp2 1/1 Running 0 4h46m 172.17.0.4 cluster-a-m02 <none> <none> calico-system calico-typha-85cdb594bc-h787v 1/1 Running 0 115m 172.17.0.6 cluster-a-m04 <none> <none> calico-system calico-typha-85cdb594bc-xh8m9 1/1 Running 0 4h55m 172.17.0.3 cluster-a <none> <none> default echoserver-6558697d87-2j56w 1/1 Running 0 4h50m 10.200.97.6 cluster-a <none> <none> kube-system coredns-78fcd69978-8ghx6 1/1 Running 0 6h10m 10.200.97.0 cluster-a <none> <none> kube-system etcd-cluster-a 1/1 Running 0 6h10m 172.17.0.3 cluster-a <none> <none> kube-system kube-apiserver-cluster-a 1/1 Running 0 6h10m 172.17.0.3 cluster-a <none> <none> kube-system kube-controller-manager-cluster-a 1/1 Running 0 6h10m 172.17.0.3 cluster-a <none> <none> kube-system kube-proxy-bl5db 1/1 Running 0 4h45m 172.17.0.6 cluster-a-m04 <none> <none> kube-system kube-proxy-ljdwm 1/1 Running 0 4h45m 172.17.0.5 cluster-a-m03 <none> <none> kube-system kube-proxy-r86h9 1/1 Running 0 4h46m 172.17.0.4 cluster-a-m02 <none> <none> kube-system kube-proxy-zpdpg 1/1 Running 0 6h10m 172.17.0.3 cluster-a <none> <none> kube-system kube-scheduler-cluster-a 1/1 Running 0 6h10m 172.17.0.3 cluster-a <none> <none> kube-system storage-provisioner 1/1 Running 1 (6h9m ago) 6h10m 172.17.0.3 cluster-a <none> <none> tigera-operator tigera-operator-b78466769-gmznr 1/1 Running 0 4h55m 172.17.0.3 cluster-a <none> <none> chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─651─▶ kubectl --cluster=cluster-a get services -A -o wide NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR calico-apiserver calico-api ClusterIP 10.201.214.10 <none> 443/TCP 4h53m apiserver=true calico-system calico-kube-controllers-metrics ClusterIP 10.201.87.46 <none> 9094/TCP 4h53m k8s-app=calico-kube-controllers calico-system calico-typha ClusterIP 10.201.184.6 <none> 5473/TCP 4h55m k8s-app=calico-typha default echoserver-external LoadBalancer 10.201.15.6 <pending> 8385:32423/TCP 4h50m app=echoserver default kubernetes ClusterIP 10.201.0.1 <none> 443/TCP 6h10m <none> kube-system kube-dns ClusterIP 10.201.0.10 <none> 53/UDP,53/TCP,9153/TCP 6h10m k8s-app=kube-dns
There’s nothing specific to report; everything looks great! Now let’s examine cluster-a’s BGP peerings (refer back to the diagram to make sense of these).
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─652─▶ for i in cluster-a cluster-a-m02 cluster-a-m03 cluster-a-m04; do minikube ssh -p cluster-a -n $i "sudo calicoctl node status"; done Calico process is running. IPv4 BGP status +---------------------+---------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +---------------------+---------------+-------+----------+-------------+ | 172.17.0.5.port.179 | node specific | up | 16:24:57 | Established | | 172.17.0.6.port.179 | node specific | up | 16:24:57 | Established | +---------------------+---------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found. Calico process is running. IPv4 BGP status +---------------------+---------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +---------------------+---------------+-------+----------+-------------+ | 172.17.0.5.port.179 | node specific | up | 16:24:58 | Established | | 172.17.0.6.port.179 | node specific | up | 16:24:58 | Established | +---------------------+---------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found. Calico process is running. IPv4 BGP status +---------------------+---------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +---------------------+---------------+-------+----------+-------------+ | 172.17.0.3.port.179 | node specific | up | 16:24:57 | Established | | 172.17.0.4.port.179 | node specific | up | 16:24:57 | Established | | 172.17.0.6.port.179 | node specific | up | 16:24:57 | Established | | 172.17.0.9 | node specific | up | 16:34:19 | Established | | 172.17.0.10 | node specific | up | 16:34:19 | Established | +---------------------+---------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found. Calico process is running. IPv4 BGP status +---------------------+---------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +---------------------+---------------+-------+----------+-------------+ | 172.17.0.3.port.179 | node specific | up | 16:24:57 | Established | | 172.17.0.4.port.179 | node specific | up | 16:24:57 | Established | | 172.17.0.5.port.179 | node specific | up | 16:24:57 | Established | | 172.17.0.9 | node specific | up | 16:34:19 | Established | | 172.17.0.10 | node specific | up | 16:34:19 | Established | +---------------------+---------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found.
In the interest of respecting your valuable time, I won’t repeat the same commands on cluster-b; but suffice to say it’s the mirror image of cluster-a and all looks well.
Finally, let’s look at the actual routing tables of the 4 nodes in cluster-a. Note that all of the nodes have routes for subnets in 10.210.0.0/16 and 10.211.0.0/16, and even better, they’re ECMP (Equal-Cost Multipath) routes, load-balanced to both of cluster-b’s route reflectors.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─659─▶ for i in cluster-a cluster-a-m02 cluster-a-m03 cluster-a-m04; do echo "-----"; minikube ssh -p cluster-a -n $i "ip route"; done ----- default via 172.17.0.1 dev eth0 10.85.0.0/16 dev cni0 proto kernel scope link src 10.85.0.1 linkdown 10.200.1.0/24 via 172.17.0.4 dev eth0 10.200.2.0/24 via 172.17.0.5 dev eth0 10.200.3.0/24 via 172.17.0.6 dev eth0 10.200.97.0 dev calie0032898db3 scope link blackhole 10.200.97.0/26 proto bird 10.200.97.1 dev calidd2cd8fe306 scope link 10.200.97.4 dev cali2440e7c7525 scope link 10.200.97.5 dev cali400773739b2 scope link 10.200.97.6 dev cali82c78c9d9a3 scope link 10.210.0.0/24 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.210.1.0/24 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.210.2.0/24 via 172.17.0.10 dev eth0 proto bird 10.210.3.0/24 via 172.17.0.9 dev eth0 proto bird 10.210.74.0/26 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.210.139.128/26 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.211.0.0/16 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.3 172.18.0.0/16 dev docker0 proto kernel scope link src 172.18.0.1 linkdown ----- default via 172.17.0.1 dev eth0 10.200.0.0/24 via 172.17.0.3 dev eth0 10.200.2.0/24 via 172.17.0.5 dev eth0 10.200.3.0/24 via 172.17.0.6 dev eth0 10.200.97.0/26 via 172.17.0.3 dev eth0 proto bird 10.210.0.0/24 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.210.1.0/24 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.210.2.0/24 via 172.17.0.10 dev eth0 proto bird 10.210.3.0/24 via 172.17.0.9 dev eth0 proto bird 10.210.74.0/26 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.210.139.128/26 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.211.0.0/16 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.4 172.18.0.0/16 dev docker0 proto kernel scope link src 172.18.0.1 linkdown ----- default via 172.17.0.1 dev eth0 10.200.0.0/24 via 172.17.0.3 dev eth0 10.200.1.0/24 via 172.17.0.4 dev eth0 10.200.3.0/24 via 172.17.0.6 dev eth0 10.200.97.0/26 via 172.17.0.3 dev eth0 proto bird 10.210.0.0/24 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.210.1.0/24 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.210.2.0/24 via 172.17.0.10 dev eth0 proto bird 10.210.3.0/24 via 172.17.0.9 dev eth0 proto bird 10.210.74.0/26 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.210.139.128/26 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.211.0.0/16 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.5 172.18.0.0/16 dev docker0 proto kernel scope link src 172.18.0.1 linkdown ----- default via 172.17.0.1 dev eth0 10.200.0.0/24 via 172.17.0.3 dev eth0 10.200.1.0/24 via 172.17.0.4 dev eth0 10.200.2.0/24 via 172.17.0.5 dev eth0 10.200.97.0/26 via 172.17.0.3 dev eth0 proto bird 10.210.0.0/24 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.210.1.0/24 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.210.2.0/24 via 172.17.0.10 dev eth0 proto bird 10.210.3.0/24 via 172.17.0.9 dev eth0 proto bird 10.210.74.0/26 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.210.139.128/26 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 10.211.0.0/16 proto bird nexthop via 172.17.0.9 dev eth0 weight 1 nexthop via 172.17.0.10 dev eth0 weight 1 172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.6 172.18.0.0/16 dev docker0 proto kernel scope link src 172.18.0.1 linkdown
cluster-b also has equivalent routes to cluster-a.
The Victory Lap (aka “Testing”)
All that remains is to see it working, and bask in the glory.
The easiest way is to connect end-to-end, shown here from a pod in cluster-a to a pod in cluster-b, and again from a pod in cluster-a to a service in cluster-b. Here I’m testing with Nicola Kabar’s fantastically useful netshoot (you can see the license in the GitHub repo here). In order for this to work, routing must be available end-to-end, with no NAT in the path. Recall that encapsulation is disabled on both clusters, too.
chris @ chris-work ~/2021_11/calico_cluster_peer_demo [main] └─658─▶ kubectl --cluster=cluster-a run tmp-shell --rm -i --tty --image nicolaka/netshoot -- /bin/bash If you don't see a command prompt, try pressing enter. bash-5.1# curl http://10.211.116.156:8385 Request served by echoserver-6558697d87-9tl8b HTTP/1.1 GET / Host: 10.211.116.156:8385 User-Agent: curl/7.80.0 Accept: */* bash-5.1# curl http://10.210.139.128:8080 Request served by echoserver-6558697d87-9tl8b HTTP/1.1 GET / Host: 10.210.139.128:8080 User-Agent: curl/7.80.0 Accept: */* bash-5.1# exit exit Session ended, resume using 'kubectl attach tmp-shell -c tmp-shell -i -t' command when the pod is running pod "tmp-shell" deleted
As you can see, it works just fine. That’s it for this post, though we’ll be doing more with this cluster in the future. If you have a go at building an environment like this yourself, please let me know how it goes.
Cleanup
Since everything is in Minikube, cleanup is quick and easy.
chris @ chris-work ~ └─670─▶ minikube delete --all 🔥 Deleting "cluster-a" in docker ... 🔥 Removing /home/chris/.minikube/machines/cluster-a ... 🔥 Removing /home/chris/.minikube/machines/cluster-a-m02 ... 🔥 Removing /home/chris/.minikube/machines/cluster-a-m03 ... 🔥 Removing /home/chris/.minikube/machines/cluster-a-m04 ... 💀 Removed all traces of the "cluster-a" cluster. 🔥 Deleting "cluster-b" in docker ... 🔥 Removing /home/chris/.minikube/machines/cluster-b ... 🔥 Removing /home/chris/.minikube/machines/cluster-b-m02 ... 🔥 Removing /home/chris/.minikube/machines/cluster-b-m03 ... 🔥 Removing /home/chris/.minikube/machines/cluster-b-m04 ... 💀 Removed all traces of the "cluster-b" cluster. 🔥 Successfully deleted all profiles
Next Steps
As I noted previously, I will use this blog post as a basis for future content. In the meantime, if you enjoyed this blog post, you might also like to learn more about determining the best networking option for your Calico deployments, or perhaps you’d enjoy this excellent playlist of bite-size videos covering everything you need to know about Kubernetes networking.
Did you know you can become a certified Calico operator? Learn container and Kubernetes networking and security fundamentals using Calico in this free, self-paced certification course. There are additional level two courses as well, covering advanced topics!
Join our mailing list
Get updates on blog posts, workshops, certification programs, new releases, and more!


