
What is Prometheus?
Prometheus offers an open-source monitoring and alerting toolkit designed especially for microservices and containers. Prometheus monitoring lets you run flexible queries and configure real-time notifications. You can use it to gain visibility into your containerized workloads, APIs, and other distributed services and applications. Additionally, Prometheus assists with cloud-native security, by detecting irregular traffic or activity that could potentially escalate into an attack.
Monitoring metrics from Prometheus can complement broader container security practices by surfacing anomalies that warrant deeper investigation.
In this article, you will learn:
- How Prometheus Works
- Kubernetes Prometheus Pros and Cons
- Installing Prometheus on Kubernetes
- Kubernetes Prometheus Best Practices
- Kubernetes Monitoring and Observability with Calico
How Prometheus Works
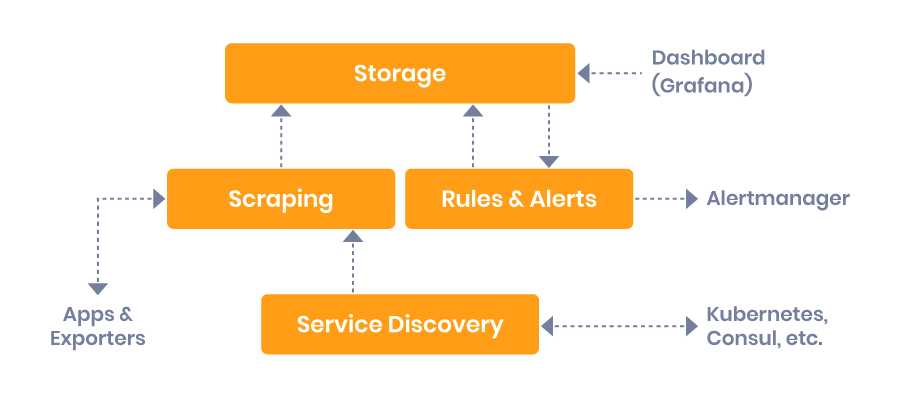
Prometheus uses a pull based system that sends HTTP requests. Each request is called a scrape, and is created according to the config instructions defined in your deployment file. Each response to a scrape is parsed and stored in a repository along with the relevant metrics.
This repository is, essentially, a custom database deployed on a server, that can handle huge amounts of data. One Prometheus server can simultaneously monitor thousands of machines.
What are Exporters?
There are two ways in which Prometheus can access data—either directly from the client libraries of your applications or indirectly through exporters.
An exporter is a software located adjacent to the application. You can use exporters to access data you do not have control over, such as kernel metrics.
Exporters are designed to do the following:
- Accept HTTP requests from Prometheus
- Ensure that the format of the data can be supported
- Serve the data requested to the Prometheus server
Which Types of Metrics does Prometheus Provide?
Prometheus provides four main types of metrics:
- Counter – Can be reset or incremented. This metric is ideal for measurements during event start or for counting the total number of events.
- Gauge – Can measure changes in either negative or positive directions. This metric is ideal for point-in-time values like memory use, in-progress requests, and temperature.
- Histogram – Can sample and categorize events with a total sum of all observed values. This metric is ideal for data aggregation.
- Summary – Can support histogram metrics, and also calculate quantiles over a sliding time window according to the total event sums and counts of observed values. This metric is ideal for generating an accurate quantile range.
Learn more in our detailed guide to Prometheus metrics
Service Discovery
Once you set up service discovery, all of your applications can provide data to Prometheus. However, you need to tell Prometheus where to look for this data. Prometheus uses service discovery to discover targets to scrape.
Kubernetes clusters are equipped with labels, annotations, and a mechanism for tracking status and changes for different elements. To discover targets, Prometheus needs to use the Kubernetes API. You can expose any Kubernetes entity to Prometheus, including nodes, services, endpoints, ingress, and pods.
Retrieving Metrics
Prometheus can retrieve machine-level metrics separately from application information. Node exporters can help expose memory, disk space, CPU utilization, and bandwidth metrics. You can also expose metrics about control groups (cgroups).
Accessing Monitoring Data
After the system completes the collection of data, you can use the PromQL query language to access the data. You can also use PromQL to export data to graphical interfaces, such as Grafana, or send alerts using Alertmanager, an alert handling component built into Prometheus. Alertmanager groups alerts and routes them to “receivers”, which may be email, PagerDuty, Opsgenie, or similar tools.
Kubernetes Prometheus Pros and Cons
Here are some of the main advantages and disadvantages of Prometheus for Kubernetes.
Pros of Prometheus:
- Built into Kubernetes – Prometheus works seamlessly with Kubernetes. Both Kubernetes and Prometheus are Cloud Native Computing Foundation (CNCF) projects and work seamlessly together (Prometheus is also bundled with Kubernetes).
- Query language and APIs – Prometheus provides APIs that enable convenient access to monitoring metrics.
- Many exporters and libraries – Prometheus offers a wide range of libraries and exporters for collecting application metrics.
- Community-developed exporters – All exporters are designed to extend the coverage of Prometheus.
- A pull-based model – The pull-based model of collecting time-series data serves as a standardized approach that simplifies the collection of data.
Cons of Prometheus:
- Pure-telemetry monitoring – Prometheus provides a simplified and constrained data model, which does not provide full context about events.
- Limited granularity – Prometheus provides summarized data scraped only periodically by exporters.
- Ideal mainly for Kubernetes – Prometheus was not designed for monitoring legacy infrastructure.
- Lack of authentication and encryption – Prometheus data collection capabilities do not come with authentication and encryption. Any user or component with access to the network can observe telemetry data.
Installing Prometheus on Kubernetes
You can configure monitoring processes on Prometheus by using YAML files, which specify permissions, configuration, and services.
Prometheus uses YAML files when accessing resources. It also helps in scraping Kubernetes cluster elements when retrieving information. Learn more about Prometheus YAML configuration in its documentation.
After the configuration is complete, you can install Prometheus as a container on a Kubernetes cluster. You can use various orchestration options to deploy these Docker containers, such as StatefulSets, Kubernetes operators, and Helm charts.
The Prometheus Operator is a popular choice that automates the deployment and management of Prometheus instances on Kubernetes.
To deploy a Prometheus server in a container, you can go to the Prometheus user interface and use the following command:
![]()
Alternatively, you can change the Docker container to a Kubernetes deployment object, which can mount the config from a ConfigMap. Here’s how:

Kubernetes Prometheus Best Practices
Here are several best practices that can help you effectively implement Prometheus in Kubernetes.
Use Consoles and Dashboards
In general, data is important, but not all of it is necessary for every scenario. Keep this in mind as you design your consoles and dashboards.
Instead of attempting to display all data within a single operational console, you should strive to display the most relevant information. You can do this by thinking about the most likely failure modes, and then represent each one in a meaningful visual display.
Restrict Use of Labels
Labels can help you refine and customize the data for your metrics. Each label set requires resources, such as RAM, disk space, bandwidth, and CPU. This data is important, but when you create labels on a large scale they consume a large amount of resources.
You can reduce costs by limiting labels on metrics to ten or less. Additionally, you should use labels only for metrics that require labels—not all do. If you do need to assign a large amount of labels to metrics, consider using dedicated analysis tools to help make the process efficient.
Use Timestamps Carefully
When tracking event timing, consider using timestamps that indicate when each event occurred rather than the time that passed since the event occured. This can help eliminate the need for updating logic and can reduce errors.
Using Pushgateway
Not all components can be scraped. To monitor these components, you can use the Prometheus Pushgateway, which enables you to push time series data from short-lived, service-level batch jobs to intermediary jobs that can be scraped. To make this instrumentation easy, you can combine this with Prometheus’s simple text-based exposition format.
Pushgateway is ideal for capturing the outcome of service-level batch jobs. It is not designed for other use cases. If you attempt to use a single Pushgateway to monitor multiple instances, for example, the Pushgateway will not only become a single point of failure but also a potential bottleneck.
Protect Your Inner Loops
When you include metrics in code that is called more than 100,000 times a second, or is performance critical, you should limit the operations you perform in the inner loop. Here are several techniques that can help you protect inner loops:
- Limit the number of metrics included in your code
- Limit the number of metrics you call in inner loops
- Do not use labels when possible
- Avoid metrics that need duration or time measurements
- Use benchmarks when measuring the impact of changes
Kubernetes Monitoring and Observability with Calico
Calico Cloud and Calico Enterprise help rapidly pinpoint and resolve performance, connectivity, and security policy issues between microservices running on Kubernetes clusters across the entire stack. They offer the following key features for Kubernetes monitoring and observability, which are not available with Prometheus:
- Dynamic Service Graph – A point-to-point, topographical representation of traffic flow and policy that shows how workloads within the cluster are communicating, and across which namespaces. Also includes advanced capabilities to filter resources, save views, and troubleshoot service issues.
- DNS Dashboard – Helps accelerate DNS-related troubleshooting and problem resolution in Kubernetes environments by providing an interactive UI with exclusive DNS metrics.
- Dynamic Packet Capture – Captures packets from a specific pod or collection of pods with specified packet sizes and duration, in order to troubleshoot performance hotspots and connectivity issues faster.
- Application-level Observability – Provides a centralized, all-encompassing view of service-to-service traffic in the Kubernetes cluster to detect anomalous behavior like attempts to access applications or restricted URLs, and scans for particular URLs.
Learn more about Calico for Kubernetes monitoring and observability