The challenges involved in deploying and managing microservices have led to the creation of the service mesh, a tool for adding observability, security, and traffic management capabilities at the application layer. While a service mesh is intended to help developers and SREs with a number of use cases related to service-to-service communication within Kubernetes clusters, a service mesh also adds operational complexity and introduces an additional control plane for security teams to manage.
What is a service mesh?
A service mesh is a software infrastructure layer for controlling and monitoring internal, service-to-service traffic in microservices applications.
Service mesh provides some of the middleware and some of the components that enable service-to-service communication, such as dynamic discovery. It provides capabilities around service discovery, load balancing traffic across services, security features around encryption and authentication, tracing observability, and more. The service mesh architecture leverages design patterns to enable communication between services without requiring microservices to rewrite applications.
Service mesh architecture
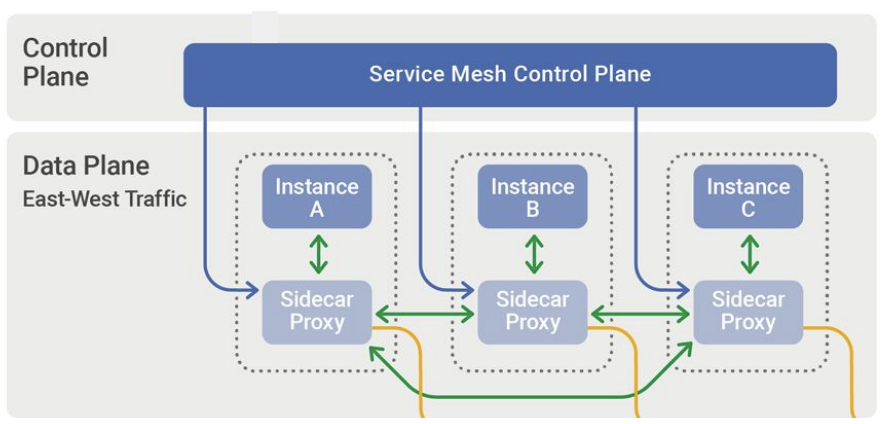
One of the key aspects of how a service mesh works is that it leverages a sidecar design pattern. Services communicate and handle requests via a proxy, which is dynamically injected into each pod. Envoy is one of the most popular proxies and is being used within service meshes for its performance, extensibility, and API facilities.
While this design pattern of a sidecar proxy makes up the data plane of a service mesh, most meshes introduce an additional control plane to configure and operate the data plane.
Control plane vs. data plane
The data plane is implemented as proxies, such as Envoy, deployed as sidecars. This means that every pod includes an instance of this proxy to mediate and control communication between microservices, and observe, collect, and report mesh traffic telemetry. All application-layer traffic is routed through the data plane.
The control plane manages and configures proxies to route traffic, and collects and consolidates data plane telemetry. While Kubernetes has its own control plane that schedules pods and handles auto-scaling of deployments, service mesh introduces another control plane to manage what these proxies are doing in order to enable service-to-service communication.
Service mesh features
Service mesh provides a powerful but complex set of features. One of the most popular open-source service meshes breaks these features down into four pillars: features to connect, secure, control, and observe. In the connect pillar, also referred to as traffic management, you get some of the advanced capabilities you might need if you’re versioning microservices and need to be able to handle various failure scenarios. The next two pillars, secure and control, are sometimes simply referred to as security. This is where a mesh provides facilities to secure traffic with mutual TLS authentication, and enforce policies on that traffic in terms of service-to-service communication. Lastly, the observe pillar covers observability features, including sidecar proxies being able to collect telemetry and logs around how services within a mesh communicate with one another.
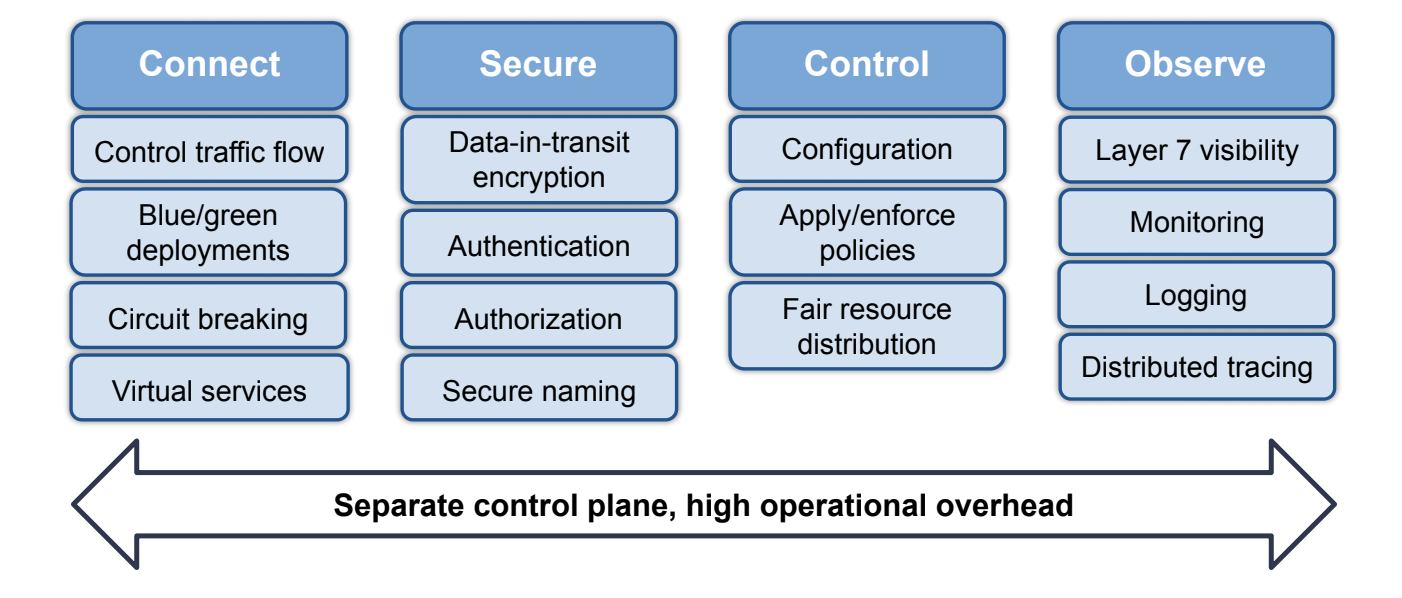
These four pillars represent a really powerful feature set; however, this power comes at a cost. Service mesh introduces an additional control plane, which causes increased deployment complexity and significant operational overhead.
Service mesh challenges
The two main challenges posed by service mesh are complexity and performance. In terms of complexity, service mesh is difficult to set up and manage. It requires specialized skills, and includes capabilities that most users don’t need. Because service mesh introduces latency, it can also create performance issues.
Many of the challenges associated with service mesh stem from the fact that there is so much to configure (the majority of the features mentioned above require some form of configuration). While there are many service meshes out there, there’s no one-size-fits-all solution when it comes to the needs of different organizations. It’s likely that security teams will need to spend a good amount of time figuring out which service mesh will work for their applications.
As such, use of a service mesh requires the development of domain knowledge and specialized skills around whichever service mesh you end up choosing. That adds another layer of complexity in addition to the work you’re already doing with Kubernetes.
Main drivers of adoption
Through conversations with DevOps teams and platform and service owners, we’ve found that there are three main use cases driving interest in service mesh adoption: security/encryption, service-level observability, and service-level control.
- Data-in-transit encryption – Security for data in transit within a cluster. Sometimes this is driven by industry-specific regulatory concerns, such as PCI compliance or HIPAA. In other cases, it is driven by internal data security requirements. When the security of internet-facing applications is at the core of an organization’s brand and reputation, security becomes extremely important.
- Service-level observability – Visibility into how workloads and services are communicating at the application layer. By design, Kubernetes is a multi-tenant environment. As more workloads and services are deployed, it becomes harder to understand how everything is working together, especially if an organization is embracing a microservices-based architecture. Service teams want to understand what their upstream and downstream dependencies are.
- Service-level control – Controlling which services can talk to one another. This includes the ability to implement best practices around a zero-trust model to ensure security.
- Secure cross-cluster connectivity – As services become shared and centralized in multi-cluster environments, securing and authorizing communication between clusters is another important requirement for platform operators.
While these are the main drivers for adoption, the complexity involved in achieving them through use of a service mesh can be a deterrent for many organizations and teams.
An operationally simpler approach
Platform owners, DevOps teams, and SREs have limited resources, so adopting a service mesh is a significant undertaking due to the resources required for configuration and operation.
Calico enables a single-pane-of-glass unified control to address the three most popular service mesh use cases—security, observability, and control—with an operationally simpler approach, while avoiding the complexities associated with deploying a separate, standalone service mesh. Let’s look at the benefits of this approach, and how you can easily achieve full-stack observability and security, deploy highly performant encryption, and tightly integrate with existing security infrastructure like firewalls.
Security
Calico offers encryption for data in transit that leverages the latest in crypto technology, using open-source WireGuard. As a result, Calico’s encryption is highly performant while still allowing visibility into all traffic flows.
One of the areas that introduces considerable operational complexity is the certificate management associated with mTLS that is used in most service meshes. WireGuard provides a highly performant alternative that requires zero configuration—even aspects such as key rotation are built into the protocol.
Observability
Calico offers visibility into service-to-service communication in a way that is resource efficient and cost effective. It provides Kubernetes-native visualizations of all the data it collects, in the form of a Dynamic Service Graph. The graph allows the user to visualize communication flows across services and team spaces, to facilitate troubleshooting. This is beneficial to platform operators, service owners, and development teams.
With Calico, Envoy is integrated into the data plane, providing operational simplicity. No matter which data plane you’re using (standard Linux iptables, Windows, or eBPF), Calico provides observability, traffic flow management, and control by deploying a single instance of Envoy as a daemon set on each node of your cluster. Instead of having an Envoy container in every pod as a sidecar, there is one Envoy container per node. This provides performance advantages, as it’s more resource efficient and cost effective.
This visibility can easily be extended to workloads outside the cluster as well.
Implementing controls
Over the years, Calico has become well-known for its capabilities around implementing controls. Now, we’ve extended these capabilities to the full stack, from the network layer up through the application layer. You get the application-layer controls you would get with a service mesh, but are able to combine those with controls you might want to implement at the network or transport layer. You can implement policies you’ve defined by assigning them to tiers that enforce an order of precedent, and each of those tiers can be tied to role-based access control (RBAC).
For example, if you want to have a security team manage certain tiers that might be geared toward PCI compliance, or monitor egress traffic and compare it against known threat feeds, you can easily do so. What’s more, you can put those policies in place without interfering with what you might want to enable your application and development teams to do for east-west traffic and service-to-service communication, which service mesh typically handles.
Calico also offers some powerful capabilities related to egress access controls. The capabilities make it easy to integrate with firewalls or other kinds of controls where you might want to understand the origin of egress traffic, and implement certain controls around that. If you’re working with a SIEM or other log management system or monitoring tool, it’s really helpful to be able to identify the origin of egress traffic, to the point where you have visibility into the specific application or namespace from which egress traffic seen outside the cluster came.
Cluster mesh and federation
Calico provides a cluster mesh that can be used to federate the identity of endpoints and services across clusters, allowing teams to define Calico policies that explicitly authorize and secure the cross-cluster communication that is required as more shared services and APIs become centralized. This allows platform owners to realize all of the benefits of a multi-cluster environment without incurring the overhead of operating a service mesh in each cluster.
Kubernetes itself presents a lot of challenges, and working through getting Kubernetes up and running keeps security teams quite busy. Calico is able address some of the most popular service mesh use cases, without introducing an additional control plane. This makes it operationally a lot simpler to handle, especially if your team has limited resources.
Summary
So… Do you really need a service mesh? In my opinion, if security and observability are your primary drivers, the answer is no. Calico provides granular observability and security—not just at the application layer, but across the full stack—while avoiding the operational complexities and overhead often associated with deploying a service mesh.
Want to learn more? Get started with a free Calico Cloud trial.
Join our mailing list
Get updates on blog posts, workshops, certification programs, new releases, and more!


