Extended Berkeley Packet Filter (eBPF) is a relatively new feature for Linux kernels that has many DevOps, SREs, and engineers excited. But is it a one-stop shop solution for all of your Linux kernel needs? Let’s take a look at what eBPF does well, and how it stacks up against standard Linux iptables.
What is eBPF?
eBPF is a feature available in Linux kernels that allows you to run a virtual machine inside the kernel. This virtual machine allows you to safely load programs into the kernel, in order to customize its operation. Why is this important?
In the past, making changes to the kernel was difficult: there were APIs you could call to get data, but you couldn’t influence what was inside the kernel or execute code. Instead, you had to submit a patch to the Linux community and wait for it to be approved. With eBPF, you can load a program into the kernel and instruct the kernel to execute your program if, for example, a certain packet is seen or another event occurs.
With eBPF, the kernel and its behavior become highly customizable, instead of being fixed. This can be extremely beneficial, when used under the right circumstances.
How can eBPF be used?
There are several use cases for eBPF, including traffic control, creating network policy, connect-time load balancing, and observability.
Traffic control
Without eBPF, packets use the standard Linux networking path on their way to a final destination. If a packet shows up at point A, and you know that the packet needs to go to point B, you can optimize the network path in the Linux kernel by sending it straight to point B. With eBPF, you can leverage additional context to make these changes in the kernel so that packets bypass complex routing and simply arrive at their final destination.
This is especially relevant in a Kubernetes container environment, where you have numerous networks. (In addition to the host network stack, each container has its own mini network stack.) When traffic comes in, it is usually routed to a container stack and must travel a complex path as it makes its way there from the host stack. This routing can be bypassed using eBPF.
Creating network policy
When creating network policy, there are two instances where eBPF can be used:
- eXpress Data Path (XDP) – As a raw packet buffer enters the system, eBPF gives you an efficient way to examine that buffer and make quick decisions about what to do with it.
- Network policy – eBPF allows you to efficiently examine a packet and apply network policy, both for pods and hosts.
Connect-time load balancing
When load balancing service connections in Kubernetes, a port needs to talk to a service and therefore network address translation (NAT) must occur. A packet is sent to a virtual IP, and that virtual IP translates it to the destination IP of the pod backing the service; the pod then responds to the virtual IP and the return packet is translated back to the source.
With eBPF, you can avoid this packet translation by using an eBPF program that you’ve loaded into the kernel and load balancing at the source of the connection. All NAT overhead from service connections is removed because destination network address translation (DNAT) does not need to take place on the packet processing path.
Observability
Collecting statistics and deep-dive debugging of the kernel are two useful ways in which eBPF can be used for observability. eBPF programs can be attached to a number of different functions in the kernel, providing access to data that a function is processing while also allowing that data to be modified. For example, with eBPF, if a network connection is established, you can receive a call when the socket is created. Why is this important when you can already receive socket calls as events? The key here is that eBPF provides these calls within the context of the program that opened the socket, so you get information about which process opened it and what happened to the socket.
The price of performance
So is eBPF more efficient than standard Linux iptables? The short answer: it depends.
If you were to micro-benchmark how iptables works when applying network policies with a large number of IP addresses (i.e. ipsets), iptables in many cases is better than eBPF. But if you want to do something in the Linux kernel where you need to alter the packet flow in the kernel, eBPF would be the better choice. Standard Linux iptables is a complex system and certainly has its limitations, but at the same time it provides options to manipulate traffic; if you know how to program iptables rules, you can achieve a lot. eBPF allows you to load your own programs into the kernel to influence behavior that can be customized to your needs, so it is more flexible than iptables as it is not limited to one set of rules.
Something else to consider is that, while eBPF allows you to run a program, add logic, redirect flows, and bypass processing—which is a definite win—it’s a virtual machine and as such must be translated to bytecode. By comparison, the Linux kernel’s iptables is already compiled to code.
As you can see, comparing eBPF to iptables is not a straight apples-to-apples comparison. What we need to assess is performance, and the two key factors to look at here are latency (speed) and expense. If eBPF is very fast but takes up 80% of your resources, then it’s like a Lamborghini—an expensive, fast car. And if that works for you, great (maybe you really like expensive, fast cars). Just keep in mind that more CPU usage means more money spent with your cloud providers. So while a Lamborghini might be faster than a lot of other cars, it might not be the best use of money if you need to comply with speed limits on your daily commute.

When to use eBPF (and when not to)
With eBPF, you get performance—but it comes at a cost. You need to find a balance between the two by figuring out the price of performance, and deciding if it’s acceptable to you from an eBPF perspective.
Let’s look at some specific cases where it would make sense to use eBPF, and some where it would not.
✘ When not to use eBPF
- Implementing application-layer policy – Performing deep protocol inspection and implementing application-layer policy with eBPF would not be very efficient due to the price vs performance tradeoff. You can leverage the Linux kernel’s connection tracker for implementing policy, apply your policy once per flow (whether the flow has 5 packets or 5,000 packets), and mark it in the Linux conntrack tables as either allowed or denied. You don’t need to keep checking every packet in the flow. If you were to implement policy with eBPF, which allows you to have several HTTP transactions on a single TCP connection, you would need to inspect every packet to detect these transactions and then implement layer 7 controls. To do that, you would need to execute CPU cycles, which would become expensive. A more efficient way to do this would be to get a proxy like Envoy, and use eBPF to optimize traffic to Envoy while letting Envoy translate the application protocols for you. Iptables with a proxy like Envoy is a better design for this and would be a better option in this case.
- Building a service mesh control plane – Similarly, service mesh relies on proxies like Envoy. A lot of thought has gone into designing this process over the years. The main reason for doing it this way is that, in many cases, it is not viable to do inline processing for application protocols like HTTP at the high speeds seen inside a cluster. Therefore, you should think of using eBPF to route traffic to a proxy like Envoy in an efficient way, rather than using it to replace the proxy itself.
- Packet-by-packet processing – Using eBPF to perform CPU intensive or packet-by-packet processing, such as decryption and re-encryption for encrypted flows, would not be efficient because you would need to build a structure and do a lookup for every packet, which is expensive.
✔ When to use eBPF
- XDP – eBPF provides an efficient way to examine raw packet buffers as they enter the system, allowing you to make quick decisions about what to do with them.
- Connect-time load balancing – With eBPF, you can load balance at the source using a program you’ve loaded into the kernel, instead of using a virtual IP. Since DNAT does not need to take place on the packet processing path, all NAT overhead from service connections is removed.
- Observability – eBPF programs are an excellent way to add probes as sensors in the Linux kernel to get context-rich data. This is a huge benefit, as there is no need to make changes to the kernel to enable tracing and profiling. You can easily receive socket calls within the context of the program that opened the socket, or add programs to trace syscalls in the kernel. In our opinion, observability is the use case for which eBPF is most beneficial.
Calico and eBPF
Calico Open Source offers an eBPF data plane as an alternative to our standard Linux dataplane (which is iptables based). While the standard data plane focuses on compatibility by working together with kube-proxy and your own iptables rules, the eBPF data plane focuses on performance, latency, and improving user experience with features that aren’t possible with the standard data plane.
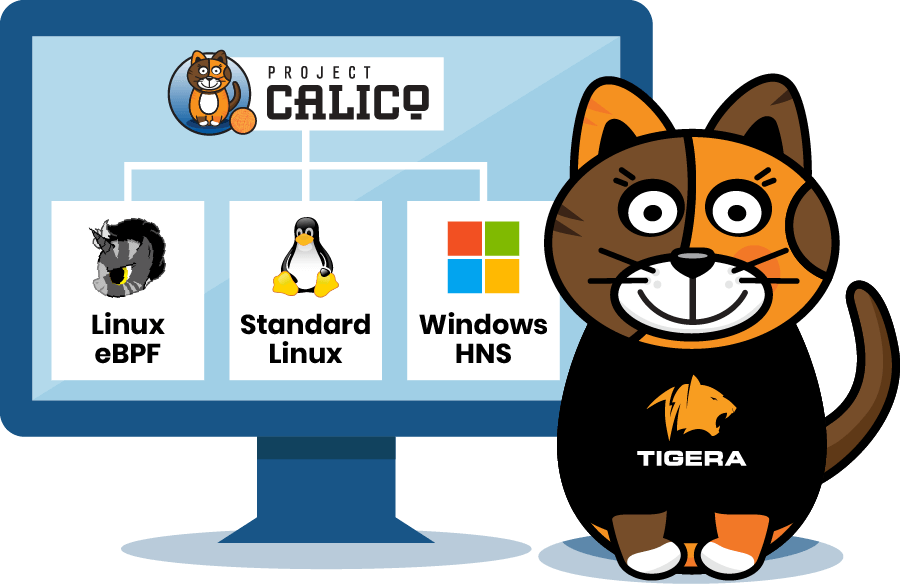
But Calico doesn’t only support standard Linux and eBPF; it currently supports a total of three data planes, including Windows HNS, and has plans to add support for even more data planes in the near future. Calico enables you, the user, to decide what works best for what you want to do.
Whether you use Calico’s eBPF data plane or not, our observability features work the same using eBPF technology. If you enable eBPF within Calico but have existing iptables flows, we won’t touch them. Because maybe you want to use connect-time load balancing, but leave iptables as is. With Calico, it’s not an all-or-nothing deal—we allow you to easily load and unload our eBPF data plane to suit your needs, which means you can quickly try it out before making a decision. Calico offers you the ability to leverage eBPF as needed, as an additional control to build your Kubernetes cluster security.
Summary
Is eBPF a replacement for iptables? Not exactly. It’s hard to imagine everything working as efficiently with eBPF as it does with iptables. For now, the two co-exist and it’s up to the user to weigh the price-performance tradeoff and decide which feature to use when, given their specific needs.
We believe the right solution is to leverage eBPF, along with existing mechanisms in the Linux kernel, to achieve your desired outcome. That’s why Calico offers support for multiple data planes, including standard Linux, Windows HNS, and Linux eBPF. Since we have established that both eBPF and iptables are useful, the only logical thing to do in our opinion is to support both. Calico gives you the choice so you can choose the best tool for the job.
Did you know you can become a certified Calico operator? Learn Kubernetes networking and security fundamentals using Project Calico in this free, self-paced certification course.
Join our mailing list
Get updates on blog posts, workshops, certification programs, new releases, and more!


