A few days ago, our team released Calico v3.16. As part of that release, we have marked the eBPF data plane as “GA”, signalling that it is now stable and ready for wider use by the community. In this blog post I want to take you through the process of moving from tech-preview to GA. If you’re not already familiar with eBPF and the benefits of the Calico eBPF data plane, or if you want to see throughput and latency graphs compared to the standard Linux data plane, I recommend that you read our introductory blog post. To recap, when compared with the standard Linux data plane (based on iptables), the eBPF data plane:
- Scales to higher throughput, using less CPU per GBit
- Natively supports Kubernetes services (without kube-proxy) in a way that:
- Reduces latency
- Preserves external client source IP addresses
- Supports DSR (Direct Server Return) for reduced latency (and CPU usage)
- Uses less CPU than kube-proxy to keep the data plane in sync
For the tech preview release, our focus was on covering a broad set of features and proving out the performance of the new data plane. However to meet the bar for GA, we had to:
- Address our list of known missing features
- Expand our end-to-end test matrix to cover eBPF mode
- Do several rounds of churn and robustness testing to verify that the new data plane functioned correctly under load for an extended period
Addressing known missing features
We knew there were various rough edges in the tech preview release including short connectivity glitches when we updated BPF programs. We worked through these issues methodically during the release cycles for v3.15 and v3.16. While the Calico eBPF data plane doesn’t support all of the features of the Calico standard Linux data plane yet (such as support for host endpoints), it also has capabilities that go beyond the standard Linux data plane (such native service handling to replace kube-proxy).
Expanding test coverage
One of the ways that we ensure the quality of Calico releases is that we run a very broad matrix of end-to-end tests against our nightly builds. At the time of writing we cover over 250 combinations of cloud provider, Kubernetes version, Kubernetes installer, encapsulation mode and (now that Windows support is released) operating system.
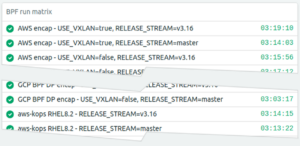
Apart from adding data plane mode to the matrix (on various cloud providers, and, with and without WireGuard encryption), we decided that we needed to write a new suite of tests to verify the eBPF-specific functionality. In particular, as the eBPF data plane replaces kube-proxy, we needed to add support for the various Kubernetes cloud providers to our automation infrastructure and then write tests to verify the various packet paths that they use. We found several bugs through this work and we now have a suite of tests that will make sure they stay fixed. Who knew that, in GCP, a background script sneaks external load balancer IPs into a hidden routing table on every node?
Churn and robustness testing
Whenever we do an impactful piece of development our Quality Engineering team put it through its paces with a series of long-running churn tests. The QE team used one of our in-house tools, the “Scale Test Operator” to hammer large and small Kubernetes clusters with pod and network policy churn, all while verifying that only expected packets were allowed through. We monitor such tests with a suite of dashboards that show the test output as well as key metrics for Calico components.
We absolutely expected the first couple of churn runs to find problems and this time was no exception; here you can see a screenshot from an early small cluster run where we hit a memory leak that led to an overload. We aim for “Time To First Ping” (TTFP) to be in the millisecond range so this was an instant fail! (TTFP is the time it takes from a new pod’s perspective to achieve end-to-end connectivity, including network policy enforcement. It’s a great measure of how quickly we are able to set up and adjust the whole network to the desired state during pod and policy churn.)
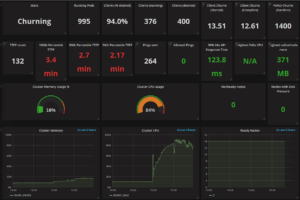
After a few rounds of fixes, here is one of our final small cluster runs with aggressive concurrent churn of pods and network policies pushing Felix several orders of magnitude harder than a normal production cluster:
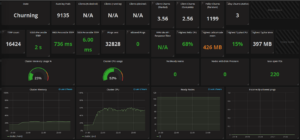
In that particular test we had a huge amount of policy loaded, causing Felix to use more RAM than usual. However, its detailed metrics were stable in spite of handling hundreds of data plane updates per second:
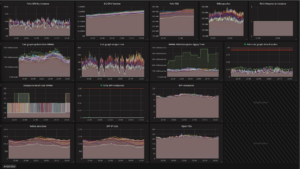
As a bonus, while running churn tests:
- We monitored the logs and invested time in reducing log spam.
- We also profiled Felix using Golang’s excellent tooling and made some targeted optimizations.
Much of that work benefits Calico’s standard Linux data plane, too.
Conclusion
For the last few months the eBPF data plane team has been focused on testing, fixing and hardening the eBPF data plane. With the help of our QE team we’ve expanded our automated end-to-end tests to cover its kube-proxy capabilities and we’ve tested it at scale with high rates of workload and network policy churn. We think it’s ready for general use.
If you are interested in trying the eBPF data plane then follow this how to guide, and, please reach out to us on slack to let us know how you got on.
————————————————-
Free Online Training
Access Live and On-Demand Kubernetes Training
Calico Enterprise – Free Trial
Network Security, Monitoring, and Troubleshooting
for Microservices Running on Kubernetes